
①、配置调试环境
该路由器使用的lighttpd版本如下:

该版本的源码可以在github上找到:https://github.com/lighttpd/lighttpd1.4/releases/tag/lighttpd-1.4.20:
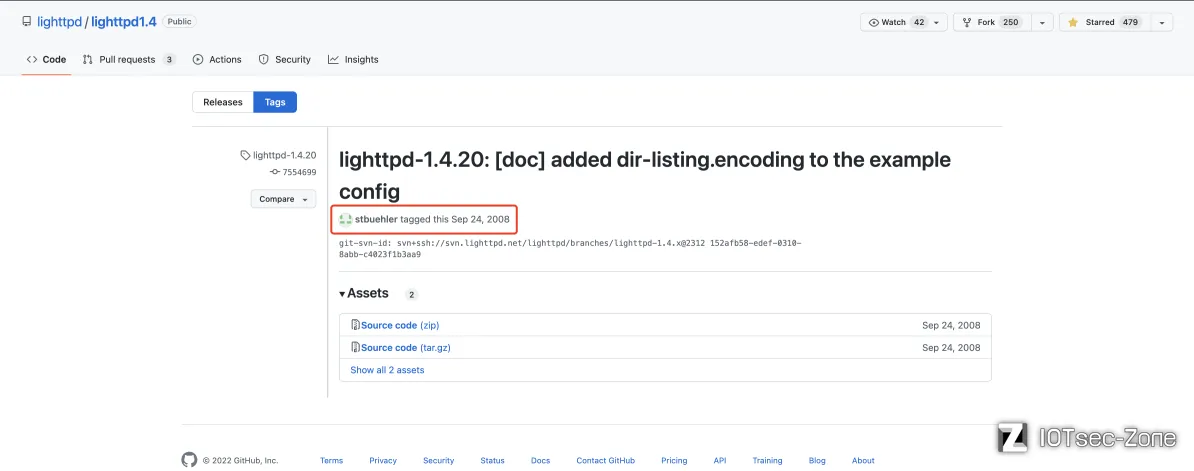
TOTOLINK真敢啊,到现在用的还是2008年的中间件!

算了,那是厂商的事,我们将源码下载下来并运行autogen.sh进行编译,发现有如下错误:
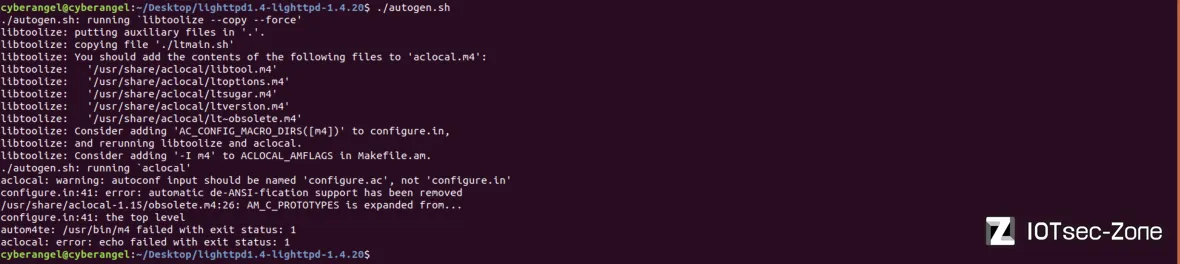
解决这个报错的方法可以在https://autotools.info/forwardporting/automake.html找到:
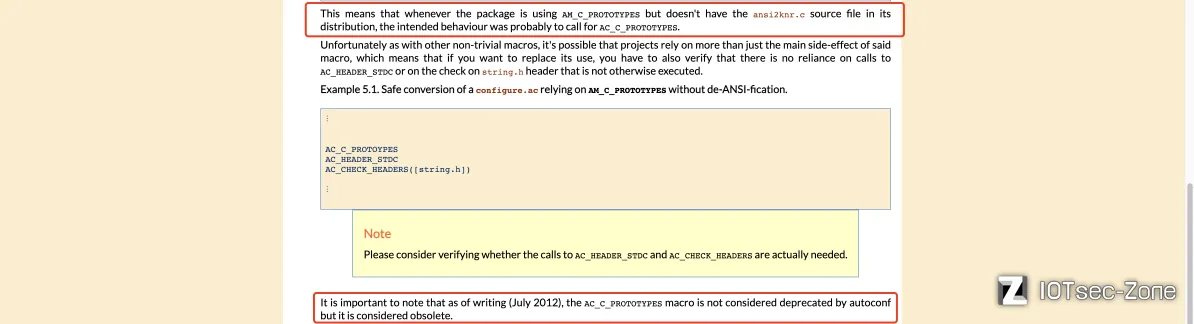
很简单,只需要将configure.in文件中的AM_C_PROTOTYPES改为AC_C_PROTOTYPES即可:

再次执行下面的命令以编译:
$ ./autogen.sh
$ ./configure -C --prefix=/usr/local # ./configure --help for additional options
# 报错------------
# configure: error: bzip2-headers and/or libs where not found, install them or build with --without-bzip2
# 解决方法:sudo apt-get install libbz2-dev
$ make -j 4
$ make check
# sudo make install
完成后可以选择执行sudo make install来安装,但是这里我就不install了。注意到在最新版本的test/README文件中有如下描述(我们下载的是没有这个README文件的):
README:https://github.com/lighttpd/lighttpd1.4/blob/master/tests/README
To run a specific config under gdb
repo=$PWD # from root of src repository
cd tests/
./prepare.sh
PERL=/usr/bin/perl SRCDIR=$repo/tests \
gdb --args $repo/src/lighttpd -D -f lighttpd.conf -m $repo/src/.libs
(gdb) start
(gdb) ...
很明显,这是gdb调试lighttpd的方法,来试一下:

访问一下,虽然图片缺失,但无伤大雅:
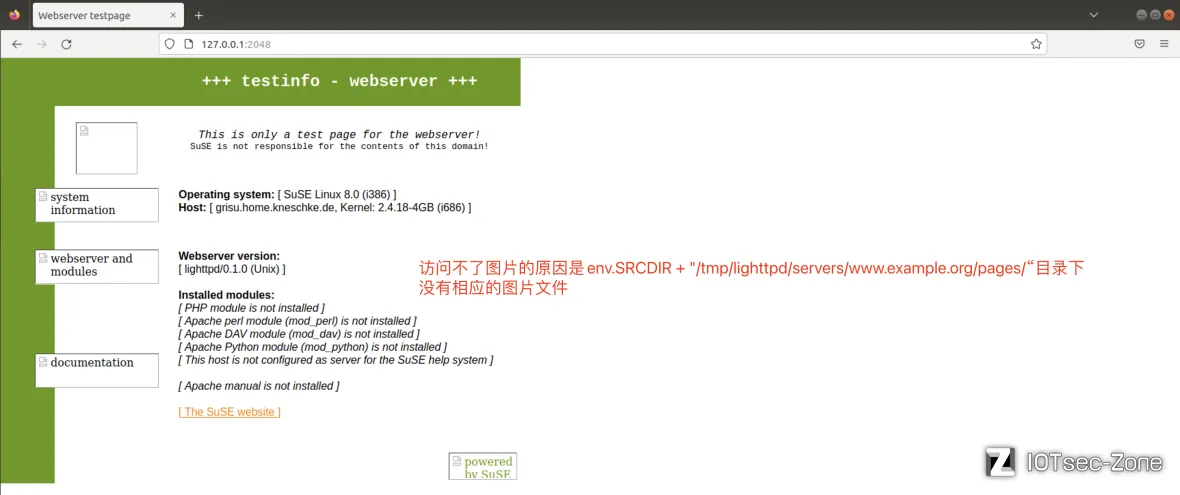
此时加载的tests/lighttpd.conf如下:
debug.log-request-handling = "enable"
debug.log-request-header = "enable"
debug.log-response-header = "enable"
debug.log-condition-handling = "enable"
server.document-root = env.SRCDIR + "/tmp/lighttpd/servers/www.example.org/pages/"
## 64 Mbyte ... nice limit
server.max-request-size = 65000
## bind to port (default: 80)
server.port = 2048
## bind to localhost (default: all interfaces)
server.bind = "localhost"
server.errorlog = env.SRCDIR + "/tmp/lighttpd/logs/lighttpd.error.log"
server.name = "www.example.org"
server.tag = "Apache 1.3.29"
server.dir-listing = "enable"
#server.event-handler = "linux-sysepoll"
#server.event-handler = "linux-rtsig"
#server.modules.path = ""
server.modules = (
"mod_rewrite",
"mod_setenv",
"mod_secdownload",
"mod_access",
"mod_auth",
# "mod_httptls",
"mod_status",
"mod_expire",
"mod_simple_vhost",
"mod_redirect",
# "mod_evhost",
# "mod_localizer",
"mod_fastcgi",
"mod_cgi",
"mod_compress",
"mod_userdir",
"mod_ssi",
"mod_accesslog" )
server.indexfiles = ( "index.php", "index.html",
"index.htm", "default.htm" )
######################## MODULE CONFIG ############################
ssi.extension = ( ".shtml" )
accesslog.filename = env.SRCDIR + "/tmp/lighttpd/logs/lighttpd.access.log"
mimetype.assign = ( ".png" => "image/png",
".jpg" => "image/jpeg",
".jpeg" => "image/jpeg",
".gif" => "image/gif",
".html" => "text/html",
".htm" => "text/html",
".pdf" => "application/pdf",
".swf" => "application/x-shockwave-flash",
".spl" => "application/futuresplash",
".txt" => "text/plain",
".tar.gz" => "application/x-tgz",
".tgz" => "application/x-tgz",
".gz" => "application/x-gzip",
".c" => "text/plain",
".conf" => "text/plain" )
$HTTP["host"] == "cache.example.org" {
compress.cache-dir = env.SRCDIR + "/tmp/lighttpd/cache/compress/"
}
compress.filetype = ("text/plain", "text/html")
setenv.add-environment = ( "TRAC_ENV" => "tracenv", "SETENV" => "setenv")
setenv.add-request-header = ( "FOO" => "foo")
setenv.add-response-header = ( "BAR" => "foo")
$HTTP["url"] =~ "\.pdf$" {
server.range-requests = "disable"
}
fastcgi.debug = 0
fastcgi.server = ( ".php" => ( ( "host" => "127.0.0.1", "port" => 1026, "broken-scriptfilename" => "enable" ) ),
"/prefix.fcgi" => ( ( "host" => "127.0.0.1", "port" => 1026, "check-local" => "disable", "broken-scriptfilename" => "enable" ) )
)
cgi.assign = ( ".pl" => "/usr/bin/perl",
".cgi" => "/usr/bin/perl",
".py" => "/usr/bin/python" )
userdir.include-user = ( "jan" )
userdir.path = "/"
ssl.engine = "disable"
ssl.pemfile = "server.pem"
$HTTP["host"] == "auth-htpasswd.example.org" {
auth.backend = "htpasswd"
}
auth.backend = "plain"
auth.backend.plain.userfile = env.SRCDIR + "/tmp/lighttpd/lighttpd.user"
auth.backend.htpasswd.userfile = env.SRCDIR + "/tmp/lighttpd/lighttpd.htpasswd"
auth.require = ( "/server-status" =>
(
"method" => "digest",
"realm" => "download archiv",
"require" => "group=www|user=jan|host=192.168.2.10"
),
"/server-config" =>
(
"method" => "basic",
"realm" => "download archiv",
"require" => "valid-user"
)
)
url.access-deny = ( "~", ".inc")
url.rewrite = ( "^/rewrite/foo($|\?.+)" => "/indexfile/rewrite.php$1",
"^/rewrite/bar(?:$|\?(.+))" => "/indexfile/rewrite.php?bar&$1" )
expire.url = ( "/expire/access" => "access 2 hours",
"/expire/modification" => "access plus 1 seconds 2 minutes")
#cache.cache-dir = "/home/weigon/wwwroot/cache/"
#### status module
status.status-url = "/server-status"
status.config-url = "/server-config"
$HTTP["host"] == "vvv.example.org" {
server.document-root = env.SRCDIR + "/tmp/lighttpd/servers/www.example.org/pages/"
secdownload.secret = "verysecret"
secdownload.document-root = env.SRCDIR + "/tmp/lighttpd/servers/www.example.org/pages/"
secdownload.uri-prefix = "/sec/"
secdownload.timeout = 120
}
$HTTP["host"] == "zzz.example.org" {
server.document-root = env.SRCDIR + "/tmp/lighttpd/servers/www.example.org/pages/"
server.name = "zzz.example.org"
}
$HTTP["host"] == "symlink.example.org" {
server.document-root = env.SRCDIR + "/tmp/lighttpd/servers/www.example.org/pages/"
server.name = "symlink.example.org"
server.follow-symlink = "enable"
}
$HTTP["host"] == "nosymlink.example.org" {
server.document-root = env.SRCDIR + "/tmp/lighttpd/servers/www.example.org/pages/"
server.name = "symlink.example.org"
server.follow-symlink = "disable"
}
$HTTP["host"] == "no-simple.example.org" {
server.document-root = env.SRCDIR + "/tmp/lighttpd/servers/123.example.org/pages/"
server.name = "zzz.example.org"
}
$HTTP["host"] !~ "(no-simple\.example\.org)" {
simple-vhost.document-root = "pages"
simple-vhost.server-root = env.SRCDIR + "/tmp/lighttpd/servers/"
simple-vhost.default-host = "www.example.org"
}
$HTTP["host"] =~ "(vvv).example.org" {
url.redirect = ( "^/redirect/$" => "http://localhost:2048/" )
}
$HTTP["host"] =~ "(zzz).example.org" {
url.redirect = ( "^/redirect/$" => "http://localhost:2048/%1" )
}
$HTTP["host"] =~ "(remoteip)\.example\.org" {
$HTTP["remoteip"] =~ "(127\.0\.0\.1)" {
url.redirect = ( "^/redirect/$" => "http://localhost:2048/%1" )
}
}
$HTTP["remoteip"] =~ "(127\.0\.0\.1)" {
$HTTP["host"] =~ "(remoteip2)\.example\.org" {
url.redirect = ( "^/redirect/$" => "http://localhost:2048/%1" )
}
}
$HTTP["host"] =~ "bug255\.example\.org$" {
$HTTP["remoteip"] == "127.0.0.1" {
url.access-deny = ( "" )
}
}
$HTTP["referer"] !~ "^($|http://referer\.example\.org)" {
url.access-deny = ( ".jpg" )
}
# deny access for all image stealers
$HTTP["host"] == "referer.example.org" {
$HTTP["referer"] !~ "^($|http://referer\.example\.org)" {
url.access-deny = ( ".png" )
}
}
$HTTP["cookie"] =~ "empty-ref" {
$HTTP["referer"] == "" {
url.access-deny = ( "" )
}
}
$HTTP["host"] == "etag.example.org" {
static-file.etags = "disable"
}
Jetbrain的clion除了编写代码之外还可以很方便进行调试,使用clion打开src文件夹,根据官方的README文件修改debug配置:
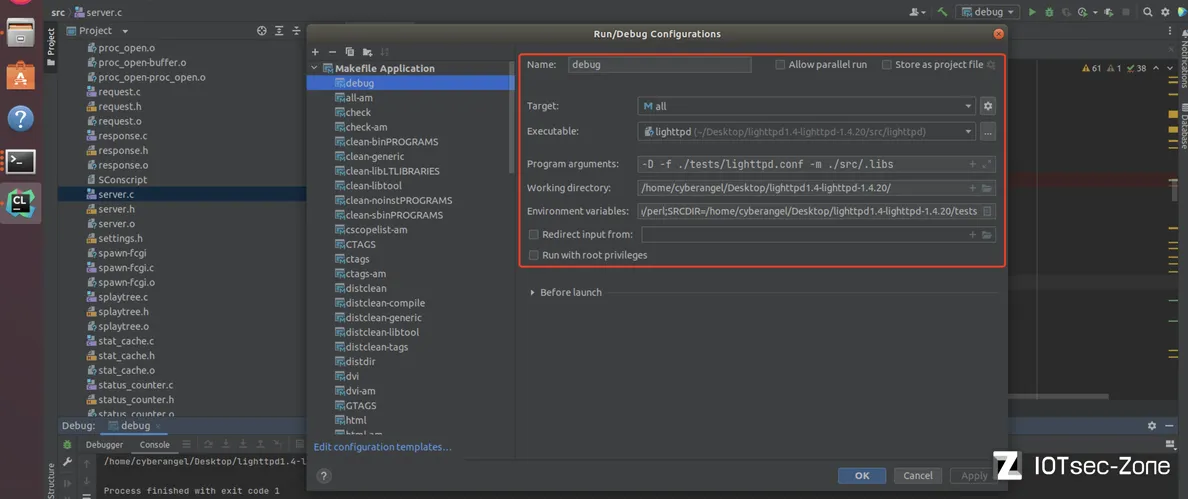
● Executable:选择lighttpd可执行文件的路径
● Program argument:-D -f ./tests/lighttpd.conf -m ./src/.libs
● Working directory:/home/cyberangel/Desktop/lighttpd1.4-lighttpd-1.4.20/
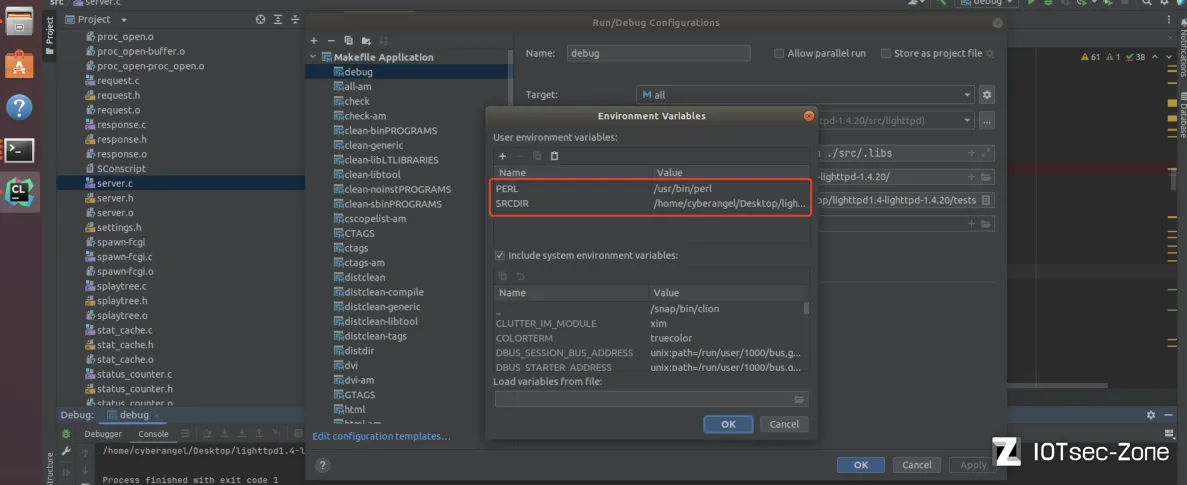
● Environment variables:PERL=/usr/bin/perl;SRCDIR=/home/cyberangel/Desktop/lighttpd1.4-lighttpd-1.4.20/tests(如下图)
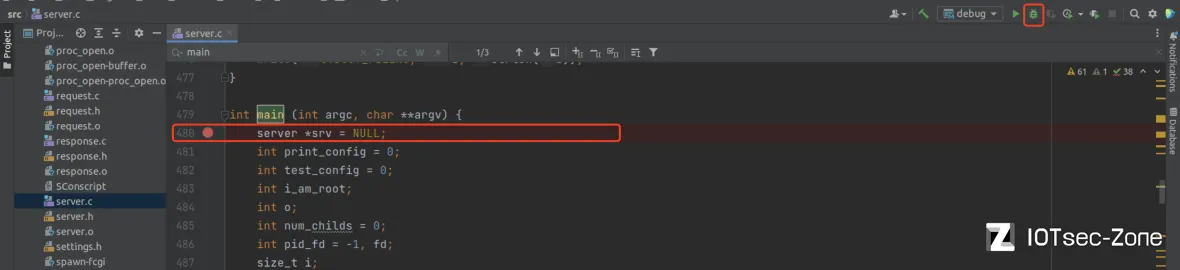
保存设置,server.c是lighttpd的主函数,对main函数下断点之后点击右上角的按钮开始调试:
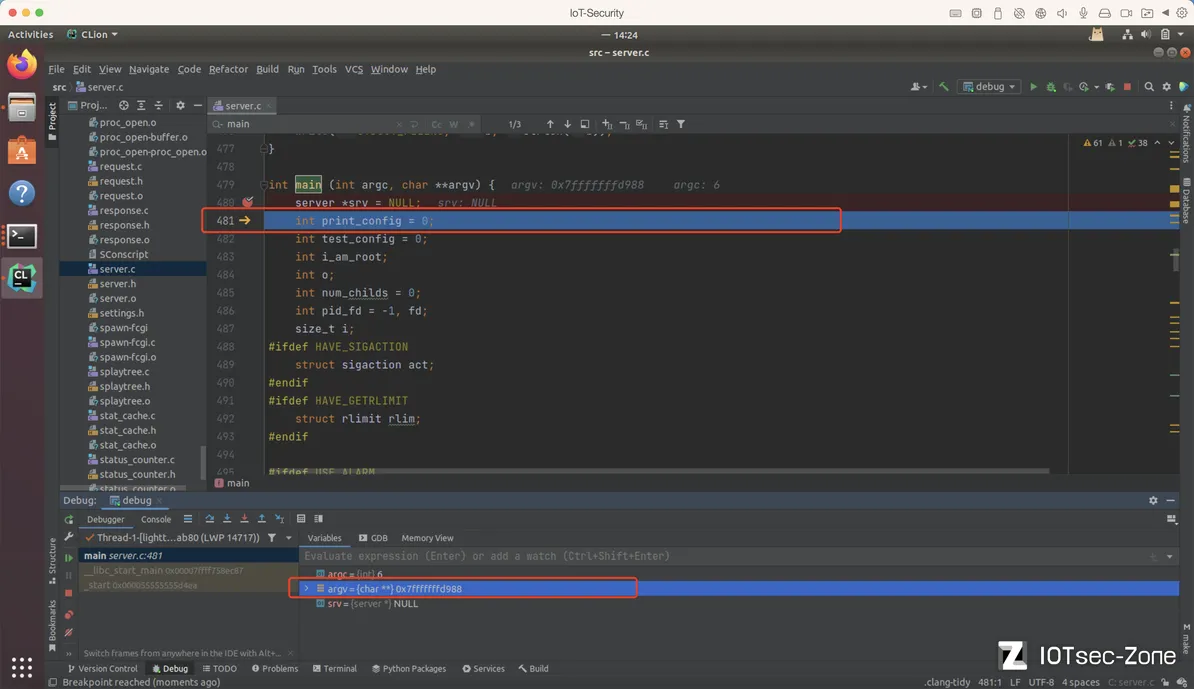
效果如下:
②、简述cgi与fastcgi之间的区别
先来讲一下cgi的基本工作原理,每当client向cgi发送请求时,server端(具体来讲是lighttpd的mod_cgi.so)会执行系统调用去fork出新的子进程(如TOTOLINK的cstecgi.cgi),并将用户请求的参数通过环境变量(environment variable)的形式传递给此子进程,子进程cgi处理完成后退出,当下一个请求来时再fork新进程,如此反复循环往复。当然了,该类cgi适用于访问量很少且没有并发的情况(如家用路由器后台),但是若访问量一旦增大,系统的开销也随之增大(主要由fork占用),这种用fork处理的方式就不适合了,于是就有了fastcgi。
fastcgi像是一个常驻(long-live)型的CGI,只要激活后它就会一直执行着,不会每次都要花费时间去fork一次。
● cgi的工作方式可以被称为fork-and-execute模式。
● 你可能注意到,在lighttpd.conf文件中还包括fastcgi的字样,即lighttpd不但支持cgi还支持fastcgi。
● 更多fastcgi的内容请参考:https://miaopei.github.io/2017/03/31/HTTP/lighttpd-fastcgi/
③、尝试自己编写cgi文件
1、入门(GET请求)
 本篇文章我们只关注cgi,先入个门吧,这里我打算自己编写一个cgi文件,默认的测试(test)的web目录为tests/tmp/lighttpd/servers/www.example.org/pages/(挺长的,但我懒得修改了:
本篇文章我们只关注cgi,先入个门吧,这里我打算自己编写一个cgi文件,默认的测试(test)的web目录为tests/tmp/lighttpd/servers/www.example.org/pages/(挺长的,但我懒得修改了:

在pages目录下编写测试代码cyberangel.c:
// 编译命令:gcc -g cyberangel.c -o cyberangel.cgi
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char *data = getenv("QUERY_STRING");
printf("User data is %s \n",data);
printf("Hello Cyberangel!\n");
return 0;
}
执行编译后修改tests/lighttpd.conf的cgi.assign选项为"",因为可执行文件的调用无需解释器:

重启lighttpd服务后浏览器访问http://127.0.0.1:2048/cyberangel.cgi?a=NYSEC:

所以,无论是POST还是GET,server都是使用环境变量向cgi进行传参,具体来讲后者通过环境变量QUERY_STRING进行的。
2、进阶(GET请求)
进一步的,下面我们做一个简单的“网页乘法计算器“,首先在pages目录下创建并编辑calculate.html:
<html>
<body>
<meta charset="utf-8">
<form ACTION="/calculate.cgi">
<P>程序功能:计算两个数的乘积,请输入两个乘数。
<INPUT NAME="m" SIZE="5">
<INPUT NAME="n" SIZE="5"><BR>
<INPUT TYPE="SUBMIT" values="提交">
</form>
</body>
</html>
对应的calculate.c的代码如下:
// 编译命令:gcc -g calculate.c -o calculate.cgi
#include <stdio.h>
#include <stdlib.h>
int main(){
char *data;
long m,n;
printf("Content-Type:text/html\n\n");
printf("<meta charset=\"utf-8\">");
printf("<TITLE>乘法结果</TITLE> ");
printf("<H3>乘法结果</H3> ");
data = getenv("QUERY_STRING"); // 获得表单get的参数m与n
if(data == NULL){
printf("<P>Error: User data is %s",data);
}
else if(sscanf(data,"m=%ld&n=%ld",&m,&n)!=2){
printf("<P>Error: User data error");
}
else{
printf("<P>%ld * %ld = %ld \n",m,n,m*n);
}
return 0;
}
最终效果如下:

访问html并输入计算:


● cgi不一定非得以.cgi文件结尾,只要是一个可执行文件就行。
● cgi返回的html标签可以被浏览器渲染,比如上面的<P>标签
3、入土(GET、POST请求)
我们对上面的代码进行修改让其支持处理GET方法与POST方法,用户在发送POST请求时携带的参数只需要从标准输入流stdin获取即可(因为有lighttpd这个“桥梁”的存在,具体原理请继续往下看):
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(){
char *data,*content_type,*request_method,*content_length;
long m,n;
int length;
printf("Content-Type:text/html\n\n");
printf("<meta charset=\"utf-8\">");
printf("<TITLE>乘法结果</TITLE> ");
printf("<H3>乘法结果</H3> ");
content_type = getenv("CONTENT_TYPE"); // 获取content_type
request_method = getenv("REQUEST_METHOD"); // 获取用户请求的方法
if(!strncasecmp(request_method, "POST", 4)){
printf("User's request_method is %s\n","POST");
content_length = getenv("CONTENT_LENGTH");
length = atoi(content_length);
data = malloc(sizeof(content_length));
fgets(data, length + 1, stdin); // 获取data(post方法)
} else if (!strncasecmp(request_method, "GET", 3)){
printf("User's request_method is %s\n","GET");
data = getenv("QUERY_STRING"); // 获得data(get方法)
} else {
printf("Undefined request method ...\n");
exit(0);
}
if(data == NULL){
printf("<P>User data is %s",data);
}
else if(sscanf(data,"m=%ld&n=%ld",&m,&n)!=2){
printf("<P>Error: User data error");
}
else{
printf("<P>%ld * %ld = %ld \n",m,n,m*n);
}
return 0;
}
同时,我们将前端改为:
<html>
<body>
<meta charset="utf-8">
<form ACTION="/calculate.cgi" method="get">
<P>程序功能:计算两个数的乘积,请输入两个乘数。(get)
<INPUT NAME="m" SIZE="5">
<INPUT NAME="n" SIZE="5"><BR>
<INPUT TYPE="SUBMIT" values="提交">
</form>
<form ACTION="/calculate.cgi" method="post">
<P>程序功能:计算两个数的乘积,请输入两个乘数。(post)
<INPUT NAME="m" SIZE="5">
<INPUT NAME="n" SIZE="5"><BR>
<INPUT TYPE="SUBMIT" values="提交">
</form>
</body>
</html>

这里只展示post方法:

4、单独运行cgi时崩溃的原因
如果你单独运行calculate.cgi发现它也会崩溃,就像TOTOLINK的cstecgi.cgi一样,因为cgi的运行依赖于环境变量,如果没有server端对cgi的环境变量的传递,则可能会导致空指针进一步造成段错误:

④、开始调试
我们已经知道cgi进程是fork出来的,所以关键在于研究lighttpd的mod_cgi.so模块,可以在src/mod_cgi.c找到相关代码:
static int cgi_create_env(server *srv, connection *con, plugin_data *p, buffer *cgi_handler) {
// (代码省略)...
/* fork, execve */
switch (pid = fork()) {
case 0: {
/* child */
// (代码省略)...
execve(args[0], args, env.ptr); /* exec the cgi */
SEGFAULT();
break;
}
// (代码省略)...
}
根据函数名称可以知道,cgi_create_env是在创建cgi的运行环境,其中的fork和excve是两个关键点:
- 通过fork函数的返回值我们可以辨别当前进程是父进程还是子进程。
- 当子进程执行execve之后会将原来的进程替换掉,放在这里就是子进程lighttpd执行execve之后会被替换为cgi进程。
如果想要使用clion调试子进程,则必须对gdb进行设置,根据https://stackoverflow.com/questions/36221038/how-to-debug-a-forked-child-process-using-clion我们有:
● set follow-fork-mode child
● set detach-on-fork off
更多详细的调试方法请参见:https://blog.csdn.net/gatieme/article/details/78309696(GDB 调试多进程或者多线程应用)
对server.c的main与mod_cgi.c的execve分别下断点:


启动调试后,在debugger框中进行设置:
此时对calculate.cgi发送post或get请求即可断下,我这里发送的是post请求:
更多execve的详细信息请参考我的另外一篇文章:https://www.yuque.com/cyberangel/rg9gdm/gbyagk,这里只摘出函数原型:
#include <unistd.h>
int execve (const char *filename, char *const argv [], char *const envp[]);

如上图所示,通过gdb我们可以得到各个参数的详细值:
/* exec the cgi */
execve(args[0], args, env.ptr);
-----
(gdb) p *args@3
$5 = {0x555555882270 "/home/cyberangel/Desktop/lighttpd1.4-lighttpd-1.4.20/tests/tmp/lighttpd/servers/www.example.org/pages/calculate.cgi", 0x0, 0x0}
(gdb) p *env.ptr@32
$12 = {
0x55555587f090 "SERVER_SOFTWARE=lighttpd/1.4.20",
0x55555587ec10 "SERVER_NAME=www.example.org",
0x555555882620 "GATEWAY_INTERFACE=CGI/1.1",
0x555555882650 "SERVER_PROTOCOL=HTTP/1.1",
0x555555882680 "SERVER_PORT=2048",
0x5555558826a0 "SERVER_ADDR=127.0.0.1",
0x5555558826c0 "REQUEST_METHOD=POST",
0x5555558826e0 "REDIRECT_STATUS=200",
0x555555882700 "REQUEST_URI=/calculate.cgi",
0x555555882730 "REMOTE_ADDR=127.0.0.1",
0x555555882750 "REMOTE_PORT=35346",
0x555555882770 "CONTENT_LENGTH=7",
0x555555882790 "SCRIPT_FILENAME=/home/cyberangel/Desktop/lighttpd1.4-lighttpd-1.4.20/tests/tmp/lighttpd/servers/www.example.org/pages/calculate.cgi",
0x555555882820 "SCRIPT_NAME=/calculate.cgi",
0x555555882850 "DOCUMENT_ROOT=/home/cyberangel/Desktop/lighttpd1.4-lighttpd-1.4.20/tests/tmp/lighttpd/servers/www.example.org/pages/",
0x555555882920 "HTTP_HOST=192.168.2.196:1234",
0x555555882950 "HTTP_CONNECTION=keep-alive",
0x555555882a90 "HTTP_CONTENT_LENGTH=7",
0x555555882ab0 "HTTP_CACHE_CONTROL=max-age=0",
0x555555882ae0 "HTTP_UPGRADE_INSECURE_REQUESTS=1",
0x555555882b10 "HTTP_ORIGIN=http://192.168.2.196:1234",
0x555555882b40 "CONTENT_TYPE=application/x-www-form-urlencoded",
0x555555882590 "HTTP_USER_AGENT=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
0x555555882b80 "HTTP_ACCEPT=text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
0x555555882c20 "HTTP_REFERER=http://192.168.2.196:1234/calculate.html",
0x555555882c60 "HTTP_ACCEPT_ENCODING=gzip, deflate",
0x555555882c90 "HTTP_ACCEPT_LANGUAGE=zh-CN,zh;q=0.9",
0x555555882cc0 "HTTP_FOO=foo",
0x555555882ce0 "TRAC_ENV=tracenv",
0x555555882d00 "SETENV=setenv",
0x0,
0x0
} // 已经手动对输出的env.ptr变量进行美化
当前Ubuntu虚拟机IP变为192.168.2.196,访问时从Ubuntu虚拟机外部访问。
此时的函数栈帧如下:
(gdb) bt
#0 cgi_create_env (srv=srv@entry=0x555555781260, con=con@entry=0x5555557cefe0, p=p@entry=0x5555557a9c60, cgi_handler=0x5555557bc5b0) at mod_cgi.c:998
#1 0x00007ffff58e0625 in cgi_is_handled (srv=0x555555781260, con=0x5555557cefe0, p_d=0x5555557a9c60) at mod_cgi.c:1199
#2 0x000055555556d1a7 in plugins_call_handle_subrequest_start (srv=srv@entry=0x555555781260, con=con@entry=0x5555557cefe0) at plugin.c:268
#3 0x000055555555df7f in http_response_prepare (srv=srv@entry=0x555555781260, con=con@entry=0x5555557cefe0) at response.c:645
#4 0x0000555555560979 in connection_state_machine (srv=srv@entry=0x555555781260, con=con@entry=0x5555557cefe0) at connections.c:1426
#5 0x000055555555c4e1 in main (argc=argc@entry=6, argv=argv@entry=0x7fffffffd988) at server.c:1432
#6 0x00007ffff758ec87 in __libc_start_main (main=0x55555555b8b0 <main>, argc=6, argv=0x7fffffffd988, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7fffffffd978) at ../csu/libc-start.c:310
#7 0x000055555555d4ea in _start ()
我们可以根据它去向前追踪cgi的完整通信过程。
1、关于cgi_create_env函数
cgi_create_env是整个lighttpd的mod_cgi.so的核心参数,用于为cgi设置环境变量、创建通信管道与cgi进程。
①、初始化父子进程通信管道
对cgi_create_env函数开头下断点,重复上述调试的步骤,并发送如下的POST请求:

192.168.2.196是Ubuntu虚拟机IP,由rinetd转发到0.0.0.0:1234
我们知道Server(lighttpd的mod_cgi.so)和Client(cgi进程)之间使用环境变量进行传参,但是只是有环境变量还不够,因为:
- 还得考虑到Server端得接收cgi处理之后返还的结果,因为我们要将结果显示到用户的浏览器上。
- GET请求可以通过QUERY_STRING去接收用户的参数,但是POST只能通过cgi的stdin去接收。
- 所以在函数开头首先定义了两个生成管道的变量用于父子进程的通信 -- to_cgi_fds[2]与from_cgi_fds[2]。一定要注意,在父进程fork出子进程后,子进程会“复制”父进程的文件描述符,因此子进程拥有与父进程相同的管道,但父子进程对其的文件描述符的操作互不影响。
if (pipe(to_cgi_fds)) { // 创建管道to_cgi_fds:其中to_cgi_fds[0]用于read、to_cgi_fds[1]用于write
// 创建失败则写入错误日志并返回
log_error_write(srv, __FILE__, __LINE__, "ss", "pipe failed:", strerror(errno));
return -1;
}
if (pipe(from_cgi_fds)) { // 创建管道from_cgi_fds:其中from_cgi_fds[0]用于read、from_cgi_fds[1]用于write
// 创建失败则写入错误日志并返回
log_error_write(srv, __FILE__, __LINE__, "ss", "pipe failed:", strerror(errno));
return -1;
}
/* fork, execve */
switch (pid = fork()) {
case 0: { // 子进程
// 在glibc的unistd.h中有如下宏定义,说白了其实就是文件描述符:
// #define STDIN_FILENO 0 /* Standard input. */
// #define STDOUT_FILENO 1 /* Standard output. */
// #define STDERR_FILENO 2 /* Standard error output. */
// 下面的代码是将parent process 与child process相连,以方便通信。
/* move stdout to from_cgi_fd[1] */
close(STDOUT_FILENO); // close(1)
dup2(from_cgi_fds[1], STDOUT_FILENO); // dup2(from_cgi_fds[write],1):
close(from_cgi_fds[1]); // close(from_cgi_fds[write]):
/* not needed */
close(from_cgi_fds[0]); // close(from_cgi_fds[read]);
/* move the stdin to to_cgi_fd[0] */
close(STDIN_FILENO); // close(0);
dup2(to_cgi_fds[0], STDIN_FILENO); // dup2(to_cgi_fds[read], 0);
close(to_cgi_fds[0]); // close(to_cgi_fds[read])
/* not needed */
close(to_cgi_fds[1]); // close(to_cgi_fds[write]);
如果你不太理解上述代码的对“管道的操作”,我简化了一下并且画了几张图,自己可以看看:https://www.iotsec-zone.com/attach_file/5a27fa4dcacb59925bed977f66242c90.zip
// 编译命令:gcc -g pipe_fork.c -o pipe_fork
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main(){
int to_cgi_fds[2];
int from_cgi_fds[2];
if (pipe(to_cgi_fds)) { // 创建管道to_cgi_fds:其中to_cgi_fds[0]用于read、to_cgi_fds[1]用于write
return -1;
}
if (pipe(from_cgi_fds)) { // 创建管道from_cgi_fds:其中from_cgi_fds[0]用于read、from_cgi_fds[1]用于write
// 创建失败则写入错误日志并返回
return -1;
}
int pid = fork();
if(pid == 0){ // 子进程
printf("child process start ...\n");
/* move stdout to from_cgi_fd[1] */ //
close(STDOUT_FILENO); // close(1)
dup2(from_cgi_fds[1], STDOUT_FILENO); // dup2(from_cgi_fds[write],1):
close(from_cgi_fds[1]); // close(from_cgi_fds[write]):
/* not needed */
close(from_cgi_fds[0]); // close(from_cgi_fds[read]);
/* move the stdin to to_cgi_fd[0] */
close(STDIN_FILENO); // close(0);
dup2(to_cgi_fds[0], STDIN_FILENO); // dup2(to_cgi_fds[read], 0);
close(to_cgi_fds[0]); // close(to_cgi_fds[read])
/* not needed */
close(to_cgi_fds[1]); // close(to_cgi_fds[write]);
} else if( pid > 0) { // 父进程
// 暂时不做处理
printf("waitting for the child process to exit.\r\n");
int status = 0;
wait(&status); //等待子进程退出
printf("the child process has exited,its exit status is %d\r\n", WEXITSTATUS(status)); // 调用宏WEXITSTATUS对status进行解析
}
printf("process end ...\n");
return 0;
}
不得不吐槽一句,子进程这管道的设置确实有点麻烦...
根据我的lighttpd.conf设置(ERRORLOG_FILE),程序会执行如下代码以将stderr重定向到“错误日志的fd”用以保存子进程的错误日志:
if (srv->errorlog_mode == ERRORLOG_FILE) {
close(STDERR_FILENO);
dup2(srv->errorlog_fd, STDERR_FILENO);
}
● 注意,下面的图只是展现了lighttpd管道的创建过程,肯定不准确,看个大概就行
然后我们切换到父进程视角,开头关闭了两个fd:
default: { // 父进程
handler_ctx *hctx;
/* father */
close(from_cgi_fds[1]);
close(to_cgi_fds[0]);
直到现在父子进程的通信过程才建立完毕:
总结:在父子进程的通信中,父进程到子进程的部分通信方式由环境变量实现(单向),双向通信则使用管道实现。pipe函数指定管道[0]是读取而[1]是写,它不像/dev/pts一样可以任意指定:
#include <stdio.h>
int main(){
char buffer[0x10]={0};
read(1,buffer,0x10); // 一般情况下我们编写代码时会写:read(0,buffer,0x10);
write(0,buffer,0x10); // 一般情况下我们编写代码时会写:write(1,buffer,0x10);
return 0;
}
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main(){
int pipe_fds[2];
char buffer1[0x10]={0};
char buffer2[0x10]={0};
pipe(pipe_fds);
printf("test1-------------------------------\n");
write(pipe_fds[0],"cyberangel\n",0x10);
read(pipe_fds[1],buffer1,0x10);
write(1,buffer1,0x10);
printf("test2-------------------------------\n");
write(pipe_fds[1],"cyberangel\n",0x10);
read(pipe_fds[0],buffer2,0x10);
write(1,buffer2,0x10);
return 0;
}
②、建立子进程运行环境并执行cgi
下面的代码逻辑很简单,大部分都是通过con结构体去设置子进程相关的环境变量,没有太大的难度,最后执行了execve:
/* create environment */
env.ptr = NULL; // char_array *env 存放有关每一个子进程(cgi)环境变量的信息,本质为结构体
env.size = 0;
env.used = 0;
cgi_env_add(&env, CONST_STR_LEN("SERVER_SOFTWARE"), CONST_STR_LEN(PACKAGE_NAME"/"PACKAGE_VERSION)); // SERVER_SOFTWARE == lighttpd/1.4.20
if (!buffer_is_empty(con->server_name)) {
cgi_env_add(&env, CONST_STR_LEN("SERVER_NAME"), CONST_BUF_LEN(con->server_name));
} else {
#ifdef HAVE_IPV6
s = inet_ntop(srv_sock->addr.plain.sa_family,
srv_sock->addr.plain.sa_family == AF_INET6 ?
(const void *) &(srv_sock->addr.ipv6.sin6_addr) :
(const void *) &(srv_sock->addr.ipv4.sin_addr),
b2, sizeof(b2)-1);
#else
s = inet_ntoa(srv_sock->addr.ipv4.sin_addr);
#endif
cgi_env_add(&env, CONST_STR_LEN("SERVER_NAME"), s, strlen(s));
} // SERVER_NAME == www.example.org
cgi_env_add(&env, CONST_STR_LEN("GATEWAY_INTERFACE"), CONST_STR_LEN("CGI/1.1")); // GATEWAY_INTERFACE=CGI/1.1
s = get_http_version_name(con->request.http_version);
cgi_env_add(&env, CONST_STR_LEN("SERVER_PROTOCOL"), s, strlen(s)); // SERVER_PROTOCOL=HTTP/1.1
LI_ltostr(buf,
#ifdef HAVE_IPV6
ntohs(srv_sock->addr.plain.sa_family == AF_INET6 ? srv_sock->addr.ipv6.sin6_port : srv_sock->addr.ipv4.sin_port)
#else
ntohs(srv_sock->addr.ipv4.sin_port)
#endif
);
cgi_env_add(&env, CONST_STR_LEN("SERVER_PORT"), buf, strlen(buf));
#ifdef HAVE_IPV6
s = inet_ntop(srv_sock->addr.plain.sa_family,
srv_sock->addr.plain.sa_family == AF_INET6 ?
(const void *) &(srv_sock->addr.ipv6.sin6_addr) :
(const void *) &(srv_sock->addr.ipv4.sin_addr),
b2, sizeof(b2)-1);
#else
s = inet_ntoa(srv_sock->addr.ipv4.sin_addr);
#endif
cgi_env_add(&env, CONST_STR_LEN("SERVER_ADDR"), s, strlen(s)); // SERVER_PORT=2048
s = get_http_method_name(con->request.http_method);
cgi_env_add(&env, CONST_STR_LEN("REQUEST_METHOD"), s, strlen(s)); // REQUEST_METHOD=POST
if (!buffer_is_empty(con->request.pathinfo)) {
cgi_env_add(&env, CONST_STR_LEN("PATH_INFO"), CONST_BUF_LEN(con->request.pathinfo));
}
cgi_env_add(&env, CONST_STR_LEN("REDIRECT_STATUS"), CONST_STR_LEN("200")); // REDIRECT_STATUS=200
if (!buffer_is_empty(con->uri.query)) {
cgi_env_add(&env, CONST_STR_LEN("QUERY_STRING"), CONST_BUF_LEN(con->uri.query));
}
if (!buffer_is_empty(con->request.orig_uri)) {
cgi_env_add(&env, CONST_STR_LEN("REQUEST_URI"), CONST_BUF_LEN(con->request.orig_uri)); // REQUEST_URI=/calculate.cgi
}
#ifdef HAVE_IPV6
s = inet_ntop(con->dst_addr.plain.sa_family,
con->dst_addr.plain.sa_family == AF_INET6 ?
(const void *) &(con->dst_addr.ipv6.sin6_addr) :
(const void *) &(con->dst_addr.ipv4.sin_addr),
b2, sizeof(b2)-1);
#else
s = inet_ntoa(con->dst_addr.ipv4.sin_addr);
#endif
cgi_env_add(&env, CONST_STR_LEN("REMOTE_ADDR"), s, strlen(s)); // REMOTE_ADDR=127.0.0.1
LI_ltostr(buf,
#ifdef HAVE_IPV6
ntohs(con->dst_addr.plain.sa_family == AF_INET6 ? con->dst_addr.ipv6.sin6_port : con->dst_addr.ipv4.sin_port)
#else
ntohs(con->dst_addr.ipv4.sin_port)
#endif
);
cgi_env_add(&env, CONST_STR_LEN("REMOTE_PORT"), buf, strlen(buf)); // REMOTE_PORT=35346
if (!buffer_is_empty(con->authed_user)) {
cgi_env_add(&env, CONST_STR_LEN("REMOTE_USER"),
CONST_BUF_LEN(con->authed_user));
}
#ifdef USE_OPENSSL
if (srv_sock->is_ssl) {
cgi_env_add(&env, CONST_STR_LEN("HTTPS"), CONST_STR_LEN("on"));
}
#endif
/* request.content_length < SSIZE_MAX, see request.c */
LI_ltostr(buf, con->request.content_length);
cgi_env_add(&env, CONST_STR_LEN("CONTENT_LENGTH"), buf, strlen(buf)); // CONTENT_LENGTH=7
cgi_env_add(&env, CONST_STR_LEN("SCRIPT_FILENAME"), CONST_BUF_LEN(con->physical.path));
// SCRIPT_FILENAME=/home/cyberangel/Desktop/lighttpd1.4-lighttpd-1.4.20/tests/tmp/lighttpd/servers/www.example.org/pages/calculate.cgi
cgi_env_add(&env, CONST_STR_LEN("SCRIPT_NAME"), CONST_BUF_LEN(con->uri.path)); // SCRIPT_NAME=/calculate.cgi
cgi_env_add(&env, CONST_STR_LEN("DOCUMENT_ROOT"), CONST_BUF_LEN(con->physical.doc_root));
// DOCUMENT_ROOT=/home/cyberangel/Desktop/lighttpd1.4-lighttpd-1.4.20/tests/tmp/lighttpd/servers/www.example.org/pages/
/* for valgrind */
if (NULL != (s = getenv("LD_PRELOAD"))) {
cgi_env_add(&env, CONST_STR_LEN("LD_PRELOAD"), s, strlen(s));
}
if (NULL != (s = getenv("LD_LIBRARY_PATH"))) {
cgi_env_add(&env, CONST_STR_LEN("LD_LIBRARY_PATH"), s, strlen(s));
}
#ifdef __CYGWIN__
/* CYGWIN needs SYSTEMROOT */
if (NULL != (s = getenv("SYSTEMROOT"))) {
cgi_env_add(&env, CONST_STR_LEN("SYSTEMROOT"), s, strlen(s));
}
#endif
// 此处省略代码,被省略的代码为cgi设置如下的环境变量,这里不再展示:
/*
// 0x555555882920 "HTTP_HOST=192.168.2.196:1234",
// 0x555555882950 "HTTP_CONNECTION=keep-alive",
// 0x555555882a90 "HTTP_CONTENT_LENGTH=7",
// 0x555555882ab0 "HTTP_CACHE_CONTROL=max-age=0",
// 0x555555882ae0 "HTTP_UPGRADE_INSECURE_REQUESTS=1",
// 0x555555882b10 "HTTP_ORIGIN=http://192.168.2.196:1234",
// 0x555555882b40 "CONTENT_TYPE=application/x-www-form-urlencoded",
// 0x555555882590 "HTTP_USER_AGENT=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
// 0x555555882b80 "HTTP_ACCEPT=text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
// 0x555555882c20 "HTTP_REFERER=http://192.168.2.196:1234/calculate.html",
// 0x555555882c60 "HTTP_ACCEPT_ENCODING=gzip, deflate",
// 0x555555882c90 "HTTP_ACCEPT_LANGUAGE=zh-CN,zh;q=0.9",
// 0x555555882cc0 "HTTP_FOO=foo",
// 0x555555882ce0 "TRAC_ENV=tracenv",
// 0x555555882d00 "SETENV=setenv",
*/
openDevNull(STDERR_FILENO); // 将stderr重定向到/dev/null(linux)、Windows则是nul
/* we don't need the client socket */
for (i = 3; i < 256; i++) {
if (i != srv->errorlog_fd) close(i); // 关闭子进程的大于等于3的fd
}
/* exec the cgi */
execve(args[0], args, env.ptr);
/* log_error_write(srv, __FILE__, __LINE__, "sss", "CGI failed:", strerror(errno), args[0]); */
/* */
SEGFAULT();
break;
}
③、父进程向子进程发送数据
其间涉及的FILE_CHUNK、 MEM_CHUNK的区别本篇文章并不讨论,两者只保留关键的代码,过程同样的十分简单:
default: {
handler_ctx *hctx;
/* father */
close(from_cgi_fds[1]); // 关闭from_cgi_fds[1]
close(to_cgi_fds[0]); // 关闭to_cgi_fds[0]
if (con->request.content_length) {
chunkqueue *cq = con->request_content_queue;
chunk *c;
assert(chunkqueue_length(cq) == (off_t)con->request.content_length);
/* there is content to send */
for (c = cq->first; c; c = cq->first) {
int r = 0;
/* copy all chunks */
switch(c->type) {
case FILE_CHUNK:
// 代码省略...
if ((r = write(to_cgi_fds[1], c->file.mmap.start + c->offset, c->file.length - c->offset)) < 0) {
// 通过向父进程的to_cgi_fds[1]写入数据,将数据发送到子进程的stdin(to_cgi_fds[0]),用来让子进程接收输入
// 若此过程中发生错误,则根据errno错误码设置返回的状态(con->http_status)
switch(errno) {
case ENOSPC:
con->http_status = 507;
break;
case EINTR:
continue;
default:
con->http_status = 403;
break;
}
}
break;
case MEM_CHUNK:
if ((r = write(to_cgi_fds[1], c->mem->ptr + c->offset, c->mem->used - c->offset - 1)) < 0) { // 这里也是一样的
switch(errno) {
case ENOSPC:
con->http_status = 507;
break;
case EINTR:
continue;
default:
con->http_status = 403;
break;
}
}
break;
case UNUSED_CHUNK:
break;
}
if (r > 0) {
c->offset += r;
cq->bytes_out += r;
} else {
log_error_write(srv, __FILE__, __LINE__, "ss", "write() failed due to: ", strerror(errno));
con->http_status = 500;
break;
}
chunkqueue_remove_finished_chunks(cq);
}
}
// 省略...
break;
}
2、关于cgi_handle_fdevent函数
cgi_handle_fdevent主要是用来接收cgi返回的数据,它注册于父进程的default分支中,当cgi处理结束之后会自动调用该函数:
default: {
handler_ctx *hctx;
// 代码省略...
fdevent_register(srv->ev, hctx->fd, cgi_handle_fdevent, hctx); // fd事件注册
fdevent_event_add(srv->ev, &(hctx->fde_ndx), hctx->fd, FDEVENT_IN); // FDEVENT_IN表示读取cgi返回的请求
// 代码省略...
break;
}
可以对cgi_handle_fdevent下个断点,重新发送请求查看栈帧,发现函数由main函数直接调用:
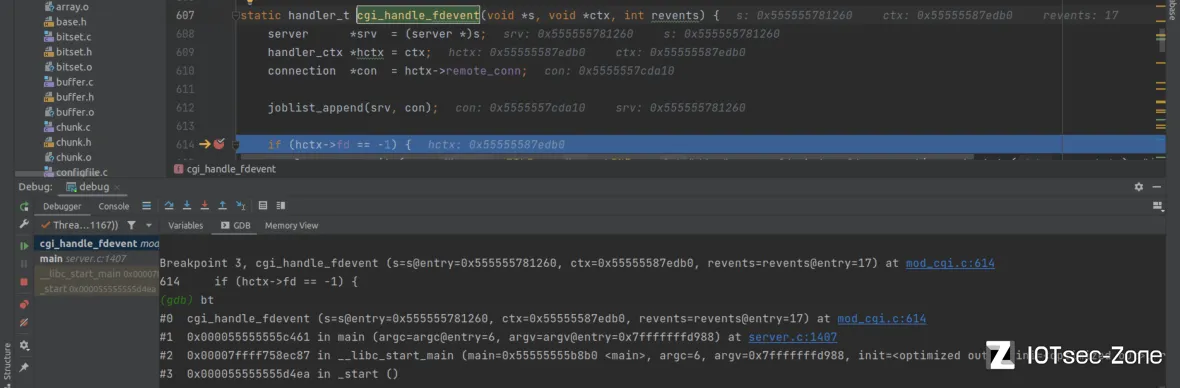
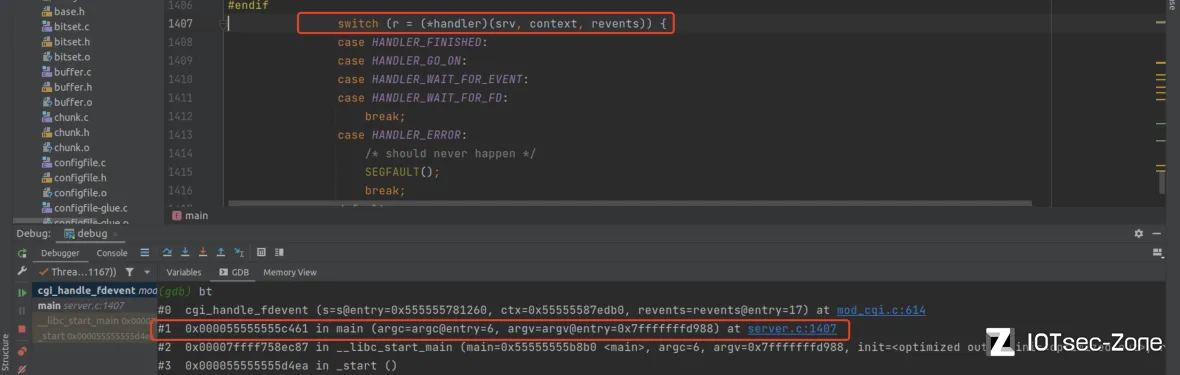
FDEVENT_IN表示读取cgi返回的请求,我们只看该部分:
static handler_t cgi_handle_fdevent(void *s, void *ctx, int revents) {
server *srv = (server *)s;
handler_ctx *hctx = ctx;
connection *con = hctx->remote_conn;
joblist_append(srv, con);
if (hctx->fd == -1) {
log_error_write(srv, __FILE__, __LINE__, "ddss", con->fd, hctx->fd, connection_get_state(con->state), "invalid cgi-fd");
return HANDLER_ERROR;
}
if (revents & FDEVENT_IN) { // 读取cgi返回的请求
switch (cgi_demux_response(srv, hctx)) {
case FDEVENT_HANDLED_NOT_FINISHED:
break;
case FDEVENT_HANDLED_FINISHED:
/* we are done */
#if 0
log_error_write(srv, __FILE__, __LINE__, "ddss", con->fd, hctx->fd, connection_get_state(con->state), "finished");
#endif
cgi_connection_close(srv, hctx);
/* if we get a IN|HUP and have read everything don't exec the close twice */
return HANDLER_FINISHED;
case FDEVENT_HANDLED_ERROR:
connection_set_state(srv, con, CON_STATE_HANDLE_REQUEST);
con->http_status = 500;
con->mode = DIRECT;
log_error_write(srv, __FILE__, __LINE__, "s", "demuxer failed: ");
break;
}
}
// 代码省略...
return HANDLER_FINISHED;
}
主要的数据处理被定义在cgi_demux_response函数中。
①、接收cgi返回的数据(响应包)
static int cgi_demux_response(server *srv, handler_ctx *hctx) {
plugin_data *p = hctx->plugin_data;
connection *con = hctx->remote_conn;
while(1) {
int n;
buffer_prepare_copy(hctx->response, 1024);
if (-1 == (n = read(hctx->fd, hctx->response->ptr, hctx->response->size - 1))) {
if (errno == EAGAIN || errno == EINTR) {
/* would block, wait for signal */
return FDEVENT_HANDLED_NOT_FINISHED;
}
/* error */
log_error_write(srv, __FILE__, __LINE__, "sdd", strerror(errno), con->fd, hctx->fd);
return FDEVENT_HANDLED_ERROR;
}
// 代码省略...
}
}
该函数的开头会使用read函数去读取cgi返回之后的数据(文件描述符为hctx->fd)到hctx->response->ptr,因为在编译的过程中gcc会将hctx优化(optimized out)掉,导致在调试的时候我们无法获取该结构体中的值,所以这里我们先记录一些地址:

hctx->fd == 10
*hctx->response = { // &hctx->response == (buffer **) 0x555555884900
// hctx->response == (buffer *) 0x555555882d50
ptr = 0x0, // &ptr == (char **) 0x555555882d50
used = 0, // &used == (size_t *) 0x555555882d58
size = 0, // &size == (size_t *) 0x555555882d60
}
同时在gdb窗口中观察到read函数的返回地址为0x00007ffff58e0a76:

下断点,调试到此处,查看:
(gdb) x/gx 0x555555882d50
0x555555882d50: 0x0000555555884920
(gdb) x/6s 0x0000555555884920
0x555555884920: "Content-Type:text/html\n\n<meta charset=\"utf-8\"><TITLE>乘法结果</TITLE> <H3>乘法结果</H3> User's request_method is POST\n<P>111 * 222 = 24642 \n"
0x5555558849b5: ""
0x5555558849b6: ""
0x5555558849b7: ""
0x5555558849b8: ""
0x5555558849b9: ""
如上所示,子进程通过pipe将结果返回给了父进程。接下来又是一大串的有关数据处理的代码,看代码似乎是为了同时兼容nph与cgi才这么长:
static int cgi_demux_response(server *srv, handler_ctx *hctx) {
plugin_data *p = hctx->plugin_data;
connection *con = hctx->remote_conn;
while(1) {
int n;
buffer_prepare_copy(hctx->response, 1024);
if (-1 == (n = read(hctx->fd, hctx->response->ptr, hctx->response->size - 1))) {
// 读取cgi返回的内容到hctx->response->ptr
}
if (n == 0) { // 当n为0时表示正文已经读取完整
/* read finished */
con->file_finished = 1;
/* send final chunk */
http_chunk_append_mem(srv, con, NULL, 0);
joblist_append(srv, con);
return FDEVENT_HANDLED_FINISHED; // 最终会在此处返回
}
hctx->response->ptr[n] = '\0';
hctx->response->used = n+1; // used表示cgi返回的请求头大小
/* split header from body */
if (con->file_started == 0) {
int is_header = 0;
int is_header_end = 0;
size_t last_eol = 0;
size_t i;
buffer_append_string_buffer(hctx->response_header, hctx->response);
/**
* we have to handle a few cases:
*
* nph:
*
* HTTP/1.0 200 Ok\n
* Header: Value\n
* \n
*
* CGI:
* Header: Value\n
* Status: 200\n
* \n
*
* and different mixes of \n and \r\n combinations
*
* Some users also forget about CGI and just send a response and hope
* we handle it. No headers, no header-content seperator
*
*/
/* nph (non-parsed headers) */
if (0 == strncmp(hctx->response_header->ptr, "HTTP/1.", 7)) is_header = 1;
for (i = 0; !is_header_end && i < hctx->response_header->used - 1; i++) {
char c = hctx->response_header->ptr[i]; // 遍历cgi返回内容的每一个字符以方便匹配处理
switch (c) {
case ':':
/* we found a colon
*
* looks like we have a normal header
*/
is_header = 1;
break;
case '\n':
/* EOL */
if (is_header == 0) {
/* we got a EOL but we don't seem to got a HTTP header */
is_header_end = 1;
break;
}
/**
* check if we saw a \n(\r)?\n sequence
*/
if (last_eol > 0 &&
((i - last_eol == 1) ||
(i - last_eol == 2 && hctx->response_header->ptr[i - 1] == '\r'))) {
is_header_end = 1;
break;
}
last_eol = i;
break;
}
}
if (is_header_end) {
if (!is_header) {
/* no header, but a body */
if (con->request.http_version == HTTP_VERSION_1_1) {
con->response.transfer_encoding = HTTP_TRANSFER_ENCODING_CHUNKED;
}
http_chunk_append_mem(srv, con, hctx->response_header->ptr, hctx->response_header->used);
joblist_append(srv, con);
} else {
const char *bstart;
size_t blen;
/**
* i still points to the char after the terminating EOL EOL
*
* put it on the last \n again
*/
i--;
/* the body starts after the EOL */
bstart = hctx->response_header->ptr + (i + 1);
blen = (hctx->response_header->used - 1) - (i + 1);
/* string the last \r?\n */
if (i > 0 && (hctx->response_header->ptr[i - 1] == '\r')) {
i--;
}
hctx->response_header->ptr[i] = '\0';
hctx->response_header->used = i + 1; /* the string + \0 */
/* parse the response header */
cgi_response_parse(srv, con, p, hctx->response_header); // 解析响应头,进入cgi_response_parse函数
/* enable chunked-transfer-encoding */
if (con->request.http_version == HTTP_VERSION_1_1 &&
!(con->parsed_response & HTTP_CONTENT_LENGTH)) {
con->response.transfer_encoding = HTTP_TRANSFER_ENCODING_CHUNKED; // 上面函数调用完成之后进入此if
}
if (blen > 0) {
http_chunk_append_mem(srv, con, bstart, blen + 1);
joblist_append(srv, con);
}
}
con->file_started = 1;
}
} else {
http_chunk_append_mem(srv, con, hctx->response->ptr, hctx->response->used);
joblist_append(srv, con);
}
#if 0
log_error_write(srv, __FILE__, __LINE__, "ddss", con->fd, hctx->fd, connection_get_state(con->state), b->ptr);
#endif
}
return FDEVENT_HANDLED_NOT_FINISHED;
}
②、处理cgi返回数据中有关响应包的header部分
就像cgi_demux_response函数中注释的一样(parse the response header),cgi_response_parse用来解析cgi返回的header,函数调用如下:
cgi_response_parse(srv, con, p, hctx->response_header); // 解析响应头,进入cgi_response_parse函数 // 函数调用
static int cgi_response_parse(server *srv, connection *con, plugin_data *p, buffer *in) { // 函数原型
/*
srv == 0x555555781260
con == 0x5555557cda10
p == 0x5555557a9c60
in == 0x5555558845c0
*/
}
// *in == {ptr = 0x555555883d70 "Content-Type:text/html\n", used = 24, size = 192}
(gdb) x/4s in->ptr
0x555555883d70: "Content-Type:text/html\n"
0x555555883d88: "<meta charset=\"utf-8\"><TITLE>乘法结果</TITLE> <H3>乘法结果</H3> User's request_method is POST\n<P>111 * 222 = 24642 \n"
0x555555883e05: ""
0x555555883e06: ""
过程很简单,这里就不再多说了,整个解析过程依赖响应包的header(p->parse_response->ptr)来处理:

cgi返回的只有Conten-Type,所以下面的循环只会进行一次:
static int cgi_response_parse(server *srv, connection *con, plugin_data *p, buffer *in) {
// 代码省略 ...
for (s = p->parse_response->ptr;
/*
(gdb) x/16s p->parse_response->ptr
0x55555587fb30: "Content-Type:text/html\n"
0x55555587fb48: ""
*/
NULL != (ns = strchr(s, '\n'));
s = ns + 1, line++) {
// 代码省略 ...
if (line == 0 &&
0 == strncmp(s, "HTTP/1.", 7)) {
/* non-parsed header ... we parse them anyway */
// 代码省略 ...
} else {
/* parse the headers */
key = s;
if (NULL == (value = strchr(s, ':'))) {
/* we expect: "<key>: <value>\r\n" */
continue;
}
key_len = value - key;
value += 1;
/* skip LWS */
while (*value == ' ' || *value == '\t') value++;
if (NULL == (ds = (data_string *)array_get_unused_element(con->response.headers, TYPE_STRING))) {
ds = data_response_init();
}
buffer_copy_string_len(ds->key, key, key_len);
buffer_copy_string(ds->value, value);
array_insert_unique(con->response.headers, (data_unset *)ds);
switch(key_len) {
case 4:
if (0 == strncasecmp(key, "Date", key_len)) { // 解析HTTP_DATE
con->parsed_response |= HTTP_DATE;
}
break;
case 6:
if (0 == strncasecmp(key, "Status", key_len)) { // 解析HTTP_STATUS
con->http_status = strtol(value, NULL, 10);
con->parsed_response |= HTTP_STATUS;
}
break;
case 8:
if (0 == strncasecmp(key, "Location", key_len)) { // 解析HTTP_LOCATION
con->parsed_response |= HTTP_LOCATION;
}
break;
case 10:
if (0 == strncasecmp(key, "Connection", key_len)) { // 解析HTTP_CONNECTION
con->response.keep_alive = (0 == strcasecmp(value, "Keep-Alive")) ? 1 : 0;
con->parsed_response |= HTTP_CONNECTION;
}
break;
case 14:
if (0 == strncasecmp(key, "Content-Length", key_len)) { // 解析HTTP_CONTENT_LENGTH
con->response.content_length = strtol(value, NULL, 10);
con->parsed_response |= HTTP_CONTENT_LENGTH;
}
break;
default:
break;
}
}
}
/* CGI/1.1 rev 03 - 7.2.1.2 */
if ((con->parsed_response & HTTP_LOCATION) &&
!(con->parsed_response & HTTP_STATUS)) { // 如果无法判断出HTTP_STATUS,则会将响应包的状态设置为302
con->http_status = 302;
}
return 0;
}
最终会在此处返回:
static int cgi_demux_response(server *srv, handler_ctx *hctx) {
plugin_data *p = hctx->plugin_data;
connection *con = hctx->remote_conn;
while(1) {
int n;
buffer_prepare_copy(hctx->response, 1024);
if (-1 == (n = read(hctx->fd, hctx->response->ptr, hctx->response->size - 1))) {
// 读取cgi返回的内容到hctx->response->ptr
}
if (n == 0) { // 当n为0时表示正文已经读取完整
/* read finished */
con->file_finished = 1;
/* send final chunk */
http_chunk_append_mem(srv, con, NULL, 0);
joblist_append(srv, con);
return FDEVENT_HANDLED_FINISHED; // 最终会在此处返回
}
// ...
}
// ...
}
现在数据处理完了,该关闭链接了,调用cgi_connection_close函数:
static handler_t cgi_handle_fdevent(void *s, void *ctx, int revents) {
server *srv = (server *)s;
handler_ctx *hctx = ctx;
connection *con = hctx->remote_conn;
joblist_append(srv, con);
if (hctx->fd == -1) {
log_error_write(srv, __FILE__, __LINE__, "ddss", con->fd, hctx->fd, connection_get_state(con->state), "invalid cgi-fd");
return HANDLER_ERROR;
}
if (revents & FDEVENT_IN) {
switch (cgi_demux_response(srv, hctx)) {
case FDEVENT_HANDLED_NOT_FINISHED:
break;
case FDEVENT_HANDLED_FINISHED:
/* we are done */
#if 0
log_error_write(srv, __FILE__, __LINE__, "ddss", con->fd, hctx->fd, connection_get_state(con->state), "finished");
#endif
cgi_connection_close(srv, hctx); // 进入此函数
/* if we get a IN|HUP and have read everything don't exec the close twice */
return HANDLER_FINISHED;
case FDEVENT_HANDLED_ERROR:
connection_set_state(srv, con, CON_STATE_HANDLE_REQUEST);
con->http_status = 500;
con->mode = DIRECT;
log_error_write(srv, __FILE__, __LINE__, "s", "demuxer failed: ");
break;
}
}
③、关闭连接并杀死子进程
整个流程如下:
static handler_t cgi_connection_close(server *srv, handler_ctx *hctx) {
int status;
pid_t pid;
plugin_data *p;
connection *con;
if (NULL == hctx) return HANDLER_GO_ON;
p = hctx->plugin_data;
con = hctx->remote_conn;
if (con->mode != p->id) return HANDLER_GO_ON;
#ifndef __WIN32
/* the connection to the browser went away, but we still have a connection
* to the CGI script
*
* close cgi-connection
*/
if (hctx->fd != -1) {
/* close connection to the cgi-script */
fdevent_event_del(srv->ev, &(hctx->fde_ndx), hctx->fd);
fdevent_unregister(srv->ev, hctx->fd);
/*
上面这两行代码对应着cgi_handle_fdevent函数的:
fdevent_register(srv->ev, hctx->fd, cgi_handle_fdevent, hctx); // fd事件注册
fdevent_event_add(srv->ev, &(hctx->fde_ndx), hctx->fd, FDEVENT_IN); // FDEVENT_IN表示读取cgi返回的请求
*/
if (close(hctx->fd)) { // close通信的文件描述符(pipe)
log_error_write(srv, __FILE__, __LINE__, "sds", "cgi close failed ", hctx->fd, strerror(errno));
}
hctx->fd = -1; // 将父进程读取子进程传来的数据的文件描述符设置为-1,设置前该值为10
hctx->fde_ndx = -1;
}
pid = hctx->pid; // 获取子进程pid
con->plugin_ctx[p->id] = NULL;
/* is this a good idea ? */
cgi_handler_ctx_free(hctx);
/* if waitpid hasn't been called by response.c yet, do it here */
if (pid) {
/* check if the CGI-script is already gone */
switch(waitpid(pid, &status, WNOHANG)) { // 检查子进程是否已经结束
case 0:
/* not finished yet */
#if 0
log_error_write(srv, __FILE__, __LINE__, "sd", "(debug) child isn't done yet, pid:", pid);
#endif
break;
case -1:
/* */
if (errno == EINTR) break;
/*
* errno == ECHILD happens if _subrequest catches the process-status before
* we have read the response of the cgi process
*
* -> catch status
* -> WAIT_FOR_EVENT
* -> read response
* -> we get here with waitpid == ECHILD
*
*/
if (errno == ECHILD) return HANDLER_GO_ON;
log_error_write(srv, __FILE__, __LINE__, "ss", "waitpid failed: ", strerror(errno));
return HANDLER_ERROR;
default:
/* Send an error if we haven't sent any data yet */
if (0 == con->file_started) {
connection_set_state(srv, con, CON_STATE_HANDLE_REQUEST);
con->http_status = 500;
con->mode = DIRECT;
}
if (WIFEXITED(status)) {
#if 0
log_error_write(srv, __FILE__, __LINE__, "sd", "(debug) cgi exited fine, pid:", pid);
#endif
pid = 0;
return HANDLER_GO_ON;
} else {
log_error_write(srv, __FILE__, __LINE__, "sd", "cgi died, pid:", pid);
pid = 0;
return HANDLER_GO_ON;
}
}
kill(pid, SIGTERM); // 若子进程无法结束则kill掉
/* cgi-script is still alive, queue the PID for removal */
cgi_pid_add(srv, p, pid);
}
#endif
return HANDLER_GO_ON;
}

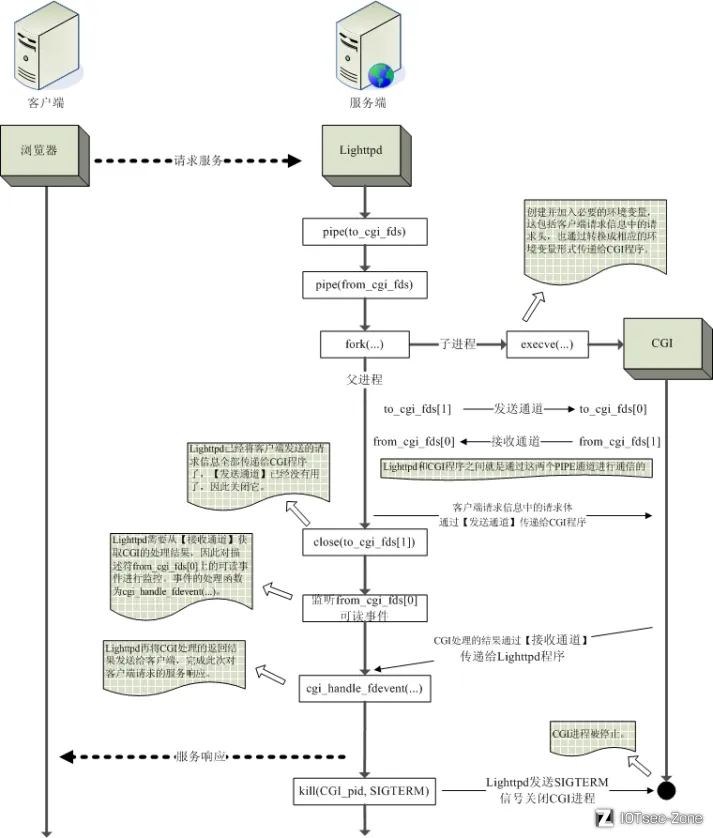
⑤、总结
一张图就能总结:
⑥、附
- lighttpd.conf各个配置项的含义请参考:https://wiki.archlinux.org/title/Lighttpd_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)
- 下面两张图是TOTOLINK的lighttpd.conf的配置情况:


- 父进程等待子进程退出:https://blog.csdn.net/anmo_moan/article/details/123563556
⑦、参考资料
- https://www.yuque.com/cyberangel/rg9gdm/gbyagk(PWN进阶(1-6)-初探调用one_gadget的约束条件(execve)
- https://www.yuque.com/cyberangel/rg9gdm/rimvzk(计算机操作系统实验知识点(NYIST)
- https://www.yanxurui.cc/posts/server/2017-01-04-write-a-cgi-program-in-c-language(用c语言编写cgi脚本)
- https://www.cnblogs.com/beacer/archive/2012/09/16/2687889.html
- https://www.cnblogs.com/wanghetao/p/3934350.html





