
在源码笔记(一)和(二)中,通过官方给的例子走完了一个fuzz的整体流程,但是其中有一些保留的地方需要继续分析。
#fuzz流程的补充分析
我们知道在session.fuzz的时候会调用_generate_mutations_indefinitely,根据已经添加到各个Request中数据生成fuzz_case_iterator,接下来看看具体是如何实现的:
def _generate_mutations_indefinitely(self, max_depth=None, path=None):
"""Yield MutationContext with n mutations per message over all messages, with n increasing indefinitely."""
depth = 1
while max_depth is None or depth <= max_depth:
valid_case_found_at_this_depth = False
for m in self._generate_n_mutations(depth=depth, path=path):
valid_case_found_at_this_depth = True
yield m
if not valid_case_found_at_this_depth:
break
depth += 1
当最大深度未被设定或者当前深度小于最大深度时,回去遍历有效路径,如果找到则深度加一,没找到则退出循环
def _generate_n_mutations(self, depth, path):
"""Yield MutationContext with n mutations per message over all messages."""
for path in self._iterate_protocol_message_paths(path=path):
for m in self._generate_n_mutations_for_path(path, depth=depth):
yield m
而_generate_n_mutations则遍历每条_iterate_protocol_message_paths生成的路径,并对每条路径进行n次变异
先看看_iterate_protocol_message_paths:
def _iterate_protocol_message_paths(self, path=None):
if not self.targets:
raise exception.SullyRuntimeError("No targets specified in session")
if not self.edges_from(self.root.id):
raise exception.SullyRuntimeError("No requests specified in session")
if path is not None:
yield path
else:
for x in self._iterate_protocol_message_paths_recursive(this_node=self.root, path=[]):
yield x
首先检查了是否至少有一个target和一个Request,如果不是的话则抛出异常。然后根据_iterate_protocol_message_paths_recursive的结果返回一个生成器。
def _iterate_protocol_message_paths_recursive(self, this_node, path):
for edge in self.edges_from(this_node.id):
path.append(edge)
message_path = self._message_path_to_str(path)
logging.debug("fuzzing: {0}".format(message_path))
self.fuzz_node = self.nodes[path[-1].dst]
yield path
for x in self._iterate_protocol_message_paths_recursive(self.fuzz_node, path):
yield x
if path:
path.pop()
_iterate_protocol_message_paths_recursive通过一种由yield实现的深度优先搜索算法,实现了找到从root出发的所有路径,由于我们执行session.fuzz()的时候没有指定要fuzz哪个具体的Request,所以这里path是none,所以在_iterate_protocol_message_paths调用_iterate_protocol_message_paths_recursive的时候给this_node的是self.root,如果之前指定了path则在上一层就直接返回了生成器。
然后来看看_generate_n_mutations_for_path
def _generate_n_mutations_for_path(self, path, depth):
"""Yield MutationContext with n mutations for a specific message.
Args:
path (list of Connection): Nodes (Requests) along the path to the current one being fuzzed.
depth (int): Yield sets of depth mutations.
Yields:
MutationContext: A MutationContext containing one mutation.
"""
for mutations in self._generate_n_mutations_for_path_recursive(path, depth=depth):
if not self._mutations_contain_duplicate(mutations):
self.total_mutant_index += 1
yield MutationContext(message_path=path, mutations={n.qualified_name: n for n in mutations})
_generate_n_mutations_for_path会遍历_generate_n_mutations_for_path_recursive,最后生成一个MutationContext的生成器。每个MutationContext包含一次变异
def _generate_n_mutations_for_path_recursive(self, path, depth, skip_elements=None):
if skip_elements is None:
skip_elements = set()
if depth == 0:
yield []
return
new_skip = skip_elements.copy()
for mutations in self._generate_mutations_for_request(path=path, skip_elements=skip_elements):
new_skip.update(m.qualified_name for m in mutations)
for ms in self._generate_n_mutations_for_path_recursive(path, depth=depth - 1, skip_elements=new_skip):
yield mutations + ms
通过递归的方式,不断调用_generate_mutations_for_request产生变异
def _generate_mutations_for_request(self, path, skip_elements=None):
if skip_elements is None:
skip_elements = []
self.fuzz_node = self.nodes[path[-1].dst]
self.mutant_index = 0
for mutations in self.fuzz_node.get_mutations(skip_elements=skip_elements):
self.mutant_index += 1
yield mutations
if self._skip_current_node_after_current_test_case:
self._skip_current_node_after_current_test_case = False
break
elif self._skip_current_element_after_current_test_case:
self.fuzz_node.mutant.stop_mutations()
self._skip_current_element_after_current_test_case = False
continue
这里又是get_mutations的wrapper
def get_mutations(self, default_value=None, skip_elements=None):
return self.mutations(default_value=default_value, skip_elements=skip_elements)
get_mutations最后会去调用self.mutations,这是Request从FuzzableBlock继承来的一个函数
def mutations(self, default_value, skip_elements=None):
if skip_elements is None:
skip_elements = []
for item in self.stack:
if item.qualified_name in skip_elements:
continue
self.request.mutant = item
for mutation in item.get_mutations():
yield mutation
skip_elements是一个用于去重的数据结构,每次从stack中取出一个item,然后调用item的get_mutations,最后生成一个mutation的生成器。
所以其实对于一次变异来说,到底如何进行取决于它是什么item。
这对我们来说是个好消息,因为这极大的简化了我们针对模型进行改进和开发的工作。
先来看看fuzzable里的get_mutations如何实现的:
def get_mutations(self):
"""Iterate mutations. Used by boofuzz framework.
Yields:
list of Mutation: Mutations
"""
try:
if not self.fuzzable:
return
index = 0
for value in itertools.chain(self.mutations(self.original_value()), self._fuzz_values):
if self._halt_mutations:
self._halt_mutations = False
return
if isinstance(value, list):
yield value
elif isinstance(value, Mutation):
yield [value]
else:
yield [Mutation(value=value, qualified_name=self.qualified_name, index=index)]
index += 1
finally:
self._halt_mutations = False # in case stop_mutations is called when mutations were exhausted anyway
index用来记录变异次数,itertools.chain将变异来的数据和传入的fuzz_values合并成一个数据结构进行遍历。_halt_mutations用来标志变异是否结束。流程走到这里,已经彻底结束了,剩下的逻辑就归入到了各种item自己内部的mutation中了。接下里我们分析一些主要用到的数据类型的变异方法都是什么。
各个类型数据的变异方法
string
以string类型为例,看看它的mutations是如何实现的:
def mutations(self, default_value):
last_val = None
for val in itertools.chain(
self._fuzz_library,
self._yield_variable_mutations(default_value),
self._yield_long_strings(self.long_string_seeds),
):
current_val = self._adjust_mutation_for_size(val)
if last_val == current_val:
continue
last_val = current_val
yield current_val
# TODO: Add easy and sane string injection from external file/s
首先将_fuzz_library、_yield_variable_mutations和_yield_long_strings三个集合通过itertools.chain合并成一个,然后去遍历,每次遍历通过_adjust_mutation_for_size调整长度,然后和上一次的value做比较,如果相同则continue,直接获取下一次变异。
来看看是如何调整长度的:
def _adjust_mutation_for_size(self, fuzz_value):
if self.max_len is not None and self.max_len < len(fuzz_value):
return fuzz_value[: self.max_len]
else:
return fuzz_value
如果设置了max_len,则检测一下当前变异出来的value的长度是否大于max_len,如果大于则直接做个截断,取前max_len个字节。
在源码中还能看到一个TODO,应该是作者想加但是还没加如boofuzz中的功能,即从外部文件中读取简单且合理的字符串注入。
所以有关strings类的一系列的变异最终都落到了那三个集合中,其中fuzz_libary是一些常用的可能有特殊含义的字符串,如reboot等

_yield_long_strings则是不断生成不同长度的long_string_seeds中的字符串的组合,long_string_seeds里是一些可能出现的合法的特殊字符:

最后是_yield_variable_mutations,它会将self.original_value()作为default_value,然后执行如下代码:
def _yield_variable_mutations(self, default_value):
for length in self._variable_mutation_multipliers:
value = default_value * length
if value not in self._fuzz_library:
yield value
if self.max_len is not None and len(value) >= self.max_len:
break
遍历_variable_mutation_multipliers中设置的长度,生成对应长度的字符串然后检查其是否在_fuzz_library中出现过,如果没有则返回生成器。_variable_mutation_multipliers定义如下:

所以其实这里就是将原来的字符串重复2遍,10遍和100遍。
看到这里是不是会发现,这变异规则有些草率吧?与其说是变异,倒不如说是用libary中的字符串以及_yield_long_strings生成的一系列长字符串去替换原有位置的string,和这个位置的字符串原来是什么其实没有太大关系。
至少现在来看,string类型是这样的,这其实正是我们可以进一步定制化开发的地方所在,当我们要针对某一个具体目标协议或设备进行fuzzing的时候,完全可以根据目标特点修改这里的fuzz_libary,或者长字符串的生成方式,又或者如果我们想要生成的测试用例主要由原来的内容变异出来,而不是简单的字典替换,可以修改_yield_variable_mutations中的逻辑,参考AFL中的一些经典的变异策略,加入变异算法从而提高fuzzing的准确率和效率。
float
def mutations(self, default_value):
last_val = None
if self.seed is not None:
random.seed(self.seed)
for i in range(self.max_mutations):
if i == 0:
current_val = default_value
else:
current_val = random.uniform(self.f_min, self.f_max)
str_format = "%" + self.s_format
current_val = str_format % float(current_val)
if last_val == current_val:
continue
last_val = current_val
yield current_val
对于float的mutation,首先是检查是否设置了随机种子,然后遍历max_mutations次,第一次直接返回默认值,后面则返回min到max之间的一个随机数,然后转成s_format的格式,s_format的默认值可以在参数中看到
def __init__(
self,
name=None,
default_value=0.0,
s_format=".1f",
f_min=0.0,
f_max=100.0,
max_mutations=1000,
seed=None,
encode_as_ieee_754=False,
endian="big",
*args,
**kwargs
):
即默认是变成保留一位的小数,如果目标有精度需求的话,可以自行设置s_format参数,所以对于float来说,所谓的变异其实就是不停的返回指定范围内的指定形式的随机数。
bytes
def mutations(self, default_value):
for fuzz_value in self._iterate_fuzz_cases(default_value):
if callable(fuzz_value):
yield compose(self._adjust_mutation_for_size, fuzz_value)
else:
yield self._adjust_mutation_for_size(fuzz_value=fuzz_value)
bytes类型中自定义的mutation中遍历的不是fuzz_libary,而是_iterate_fuzz_cases,来看看_iterate_fuzz_cases是如何实现的:
def _iterate_fuzz_cases(self, default_value):
for fuzz_value in self._fuzz_library:
yield fuzz_value
for fuzz_value in self._mutators_of_default_value:
yield fuzz_value
for fuzz_value in self._magic_debug_values:
yield fuzz_value
for i in range(0, len(default_value)):
for fuzz_bytes in self._fuzz_strings_1byte:
def f(value):
if i < len(value):
return value[:i] + fuzz_bytes + value[i + 1 :]
else:
return value
yield f
for i in range(0, len(default_value) - 1):
for fuzz_bytes in self._fuzz_strings_2byte:
def f(value):
if i < len(value) - 1:
return value[:i] + fuzz_bytes + value[i + 2 :]
else:
return value
yield f
for i in range(0, len(default_value) - 3):
for fuzz_bytes in self._fuzz_strings_4byte:
def f(value):
if i < len(value) - 3:
return value[:i] + fuzz_bytes + value[i + 4 :]
else:
return value
yield f
首先是返回三个集合_fuzz_library,_mutators_of_default_value,_magic_debug_values的生成器,然后通过三个循环,根据default_value的长度,分别生成三种函数的生成器,三种函数分别是对给定value进行1字节,2字节和4字节的遍历替换。
这里和之前不一样的地方在于字典中不再只有value,还有function,相应的,再回头看mutations的时候就会发现,它先判断了value是否是函数,如果是的话则通过compose,将函数的返回值作为_adjust_mutation_for_size的参数,如果不是函数则直接将其作为_adjust_mutation_for_size的参数,_adjust_mutation_for_size我们之前已经分析过了,就是一个检查value长度的函数,过长会根据最大长度进行截断。
最后来看看bytes的mutation过程中涉及到的一系列字典:
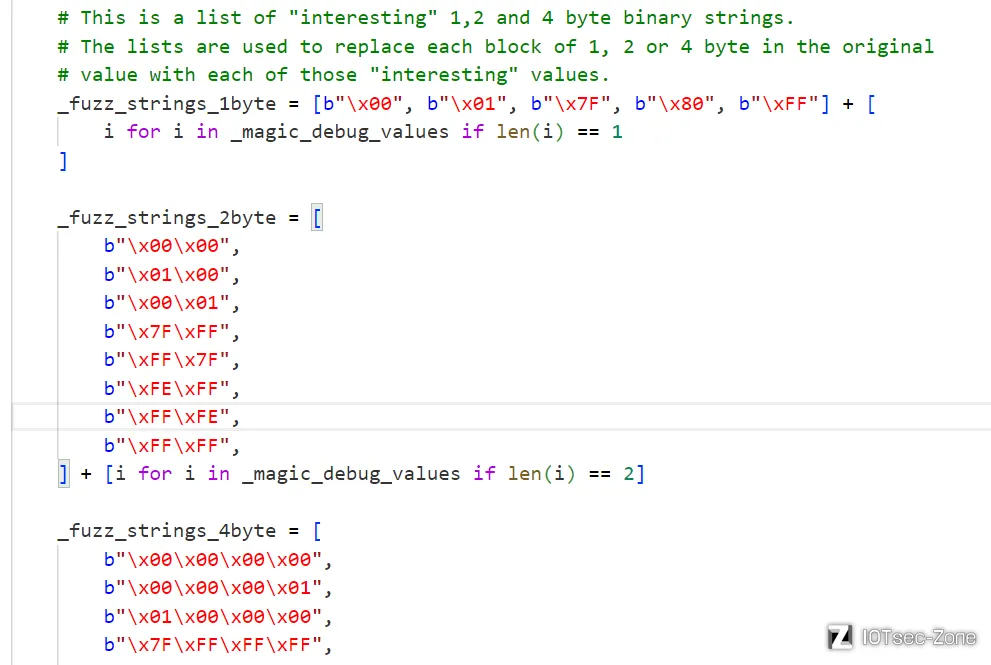
首先是用于1,2,4字节遍历替换的字典,可以看到是一些临界值以及magic_debug_values中的长度等于1,2,4的字符串

fuzz_libary里的东西相对很少,一些临界值和一些超长值,magic_debug_values里的则是从https://en.wikipedia.org/wiki/Magic_number_(programming)#Magic_debug_values
获取的一系列魔数
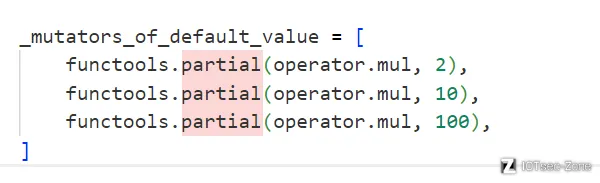
mutators_of_default_value里是这三句话,效果是将原本的value分别乘2,,10,100倍
到这里bytes的所有变异方法就分析全了。
未额外定义的变异
源码中有一部分类型是有自己实现的mutation函数,但是有一些是没有的,没有自己实现的类型是依据什么来变异的呢,我们知道其他的类型的父类是BasePrimitive或BitField,而在BasePrimitive和BitField中的mutation是这样定义的:
class BasePrimitive(Fuzzable):
"""
The primitive base class implements common functionality shared across most primitives.
"""
def __init__(self, *args, **kwargs):
super(BasePrimitive, self).__init__(*args, **kwargs)
self._fuzz_library = [] # library of static fuzz heuristics to cycle through.
def mutations(self, default_value):
for val in self._fuzz_library:
yield val
可以看到在BasePrimitive中实现了一个最基本的mutations,就是遍历_fuzz_library,而_fuzz_library也在init中初始化成了一个列表,列表中的具体内容是什么则由每个类自行设置,比如delim类:
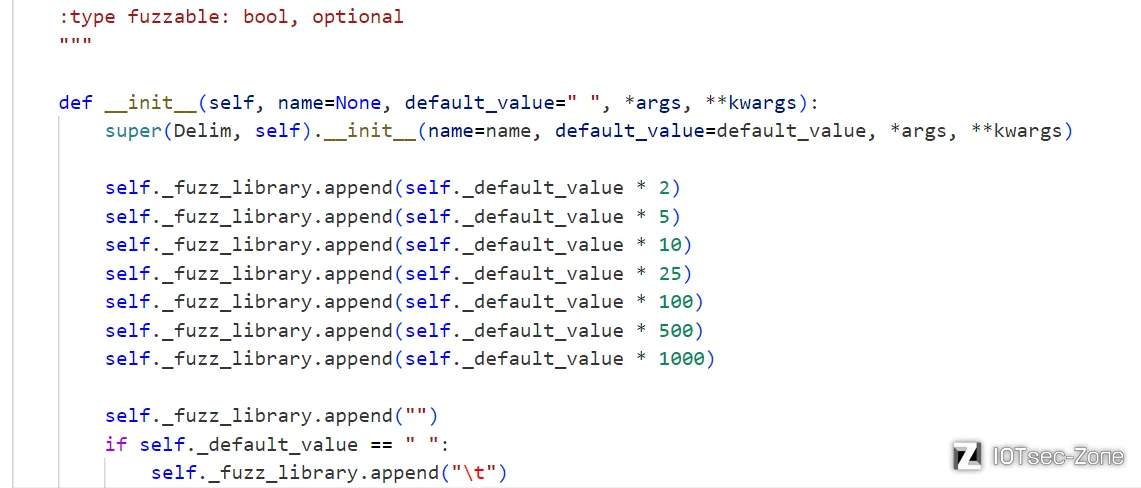
加入了作者认为可能出现问题的一系列字符串进去作为分隔符的fuzzing字典,而delim里并没有自己实现mutations,所以在fuzzing的时候就是遍历一遍这个_fuzz_library,没有其他操作。






