
背景
Unicorn 是一款基于 QEMU 的快速 CPU 模拟器框架,可以模拟多种体系结构的指令集,包括 ARM、MIPS、PowerPC、SPARC 和 x86 等。Unicorn使我们可以更好地关注 CPU 操作, 忽略机器设备的差异。它能够在虚拟内存中加载和运行二进制代码,并提供对模拟器状态的完全控制,包括内存、寄存器和标志位等。该项目最初是作为一个 QEMU 插件而启动的,但随着时间的推移,它已经成长为一款独立的模拟器框架。现在 Unicorn 在许多领域都有应用,如二进制代码分析、系统仿真、漏洞测试等。
unicorn基础
unicorn安装:
最简单的安装方式为Python PIP安装:
pip3 install unicorn
手动编译方式如下:
wget https://github.com/unicorn-engine/unicorn/archive/2.0.1.zip
unzip 2.0.1.zip
cd unicorn-2.0.1/bingings/python
sudo make install
在unicorn/bindings/python目录下,下面有官方提供的example脚本可以供我们学习。
from unicorn import *
# 在使用Unicorn前导入unicorn模块. 样例中使用了一些x86寄存器常量, 所以也需要导入unicorn.x86_const模块
from unicorn.x86_const import *
# 需要模拟的二进制机器码, 需要使用十六进制表示, 代表的汇编指令是: "INC ecx" 和 "DEC edx",即ecx+=1,edx-=1
X86_CODE32 = b"\x41\x4a" # INC ecx; DEC edx
# 我们将模拟执行上述指令的所在虚拟地址
ADDRESS = 0x80000
print("Emulate i386 code")
try:
# 使用Uc类初始化Unicorn, 该类接受2个参数: 硬件架构和32/64位(模式),在这里我们需要模拟执行x86架构的32位代码, 并使用变量mu来接受返回值。
mu = Uc(UC_ARCH_X86, UC_MODE_32)
# 使用mem_map函数根据ADDRESS映射2MB用于模拟执行的内存空间。所有进程中的CPU操作都应该只访问该内存区域,映射的内存具有默认的读,写和执行权限。
mu.mem_map(ADDRESS, 2 * 1024 * 1024)
# 将需要模拟执行的代码写入我们刚刚映射的内存中。mem_write函数2个参数: 要写入的内存地址和需要写入内存的代码。
mu.mem_write(ADDRESS, X86_CODE32)
# 使用reg_write函数设置ECX和EDX寄存器的值
mu.reg_write(UC_X86_REG_ECX, 0x1234)
mu.reg_write(UC_X86_REG_EDX, 0x7890)
# 使用emu_start方法开始模拟执行, 该函数接受4个参数: 要模拟执行的代码地址, 模拟执行停止的内存地址(这里是X86_CODE32的最后1字节处), 模拟执行的时间和需要执行的指令数目。如果我们忽略后两个参数, Unicorn将会默认以无穷时间和无穷指令数目的条件来模拟执行代码。
mu.emu_start(ADDRESS, ADDRESS + len(X86_CODE32))
# 我们使用reg_read函数来读取寄存器中的值,打印输出ECX和EDX寄存器的值。
print("Emulation done. Below is the CPU context")
r_ecx = mu.reg_read(UC_X86_REG_ECX)
r_edx = mu.reg_read(UC_X86_REG_EDX)
print(">>> ECX = 0x%x" %r_ecx)
print(">>> EDX = 0x%x" %r_edx)
except UcError as e:
print("ERROR: %s" % e)
上面的代码大致过程设置虚拟地址并初始化unicorn引擎,并设置内存映射空间,随后将要模拟执行代码写入内存虚拟空间中。程序执行前给ecx寄存器赋值为0x1234,edx寄存器赋值为0x7890,当执行emu_start函数时,程序从要模拟代码的开始进行执行。此时运行仿真代码为"INC ecx; DEC edx"。即,对ecx进行加一操作,对edx进行减一操作。运行后打印结果如下:

我们可以从项目中所有的example案例中可以提取出unicorn模板脚本:
from unicorn import *
from unicorn.x86_const import *
# 相应架构的常量信息:
# arch:UC_ARCH_ARM、UC_ARCH_ARM64、UC_ARCH_M68K、UC_ARCH_MAX、UC_ARCH_MIPS、UC_ARCH_PPC、UC_ARCH_SPARC、UC_ARCH_X86
# mode:UC_MODE_16、UC_MODE_32、UC_MODE_64、UC_MODE_ARM、UC_MODE_BIG_ENDIAN、UC_MODE_LITTLE_ENDIAN、UC_MODE_MCLASS、UC_MODE_MICRO、UC_MODE_MIPS3、UC_MODE_MIPS32、UC_MODE_MIPS32R6、UC_MODE_MIPS64、UC_MODE_PPC32、UC_MODE_PPC64、UC_MODE_QPX、UC_MODE_SPARC32、UC_MODE_SPARC64、UC_MODE_THUMB、UC_MODE_V8、UC_MODE_V9
# 该模板中的UC_ARCH_X86可替换成为其他架构的常量,且相应寄存器常量名称也要相应改变。
# 定义要执行的指令
CODE = b"\xXX"
# 指定内存地址
BASE_ADDRESS = 0x100000
# 定义hook函数
def hook_code(uc, address, size, user_data):
# 输出寄存器值和内存内容
print("[+] RIP=0x%x RAX=0x%x RBX=0x%x RCX=0x%x RDX=0x%x" % (uc.reg_read(UC_X86_REG_RIP), uc.reg_read(UC_X86_REG_RAX), uc.reg_read(UC_X86_REG_RBX), uc.reg_read(UC_X86_REG_RCX), uc.reg_read(UC_X86_REG_RDX)))
print("[+] Memory:")
for i in range(0x1000):
if uc.mem_read(BASE_ADDRESS+i, 1) != b'\x00':
print("0x%x: %s" % (BASE_ADDRESS+i, uc.mem_read(BASE_ADDRESS+i, 16).hex()))
# 初始化 Unicorn 引擎和内存空间
mu = Uc(UC_ARCH_X86, UC_MODE_64)
mu.mem_map(BASE_ADDRESS, 0x10000)
mu.mem_write(BASE_ADDRESS, CODE)
# 设置 RIP 和 RSP
mu.reg_write(UC_X86_REG_RIP, BASE_ADDRESS)
mu.reg_write(UC_X86_REG_RSP, BASE_ADDRESS + 0x10000)
# 注册hook函数
mu.hook_add(UC_HOOK_CODE, hook_code)
# 开始模拟执行
mu.emu_start(BASE_ADDRESS, BASE_ADDRESS + len(CODE))
注:函数(或钩子函数)是一种用户自定义函数,用于在模拟执行指令时对特定事件进行处理。当程序执行到某个地址时,引擎会调用已注册的 Hook 函数,并将当前的 CPU 状态、指令地址和指令大小等信息传递给函数。这样,用户就可以利用 Hook 函数来监测程序的执行状态、修改寄存器/内存值,或者实现其他自定义功能。
unicorn实例
以ctf题目为例,下载题目附件后,拖入IDA进行分析。进行main函数分析发现整个程序执行完毕后就会输出flag的值,不考虑指令集架构及运行程序的情况下,正常逆向思路便是逆向程序逻辑以及函数代码并编写相应解密程序进行运行获取flag。
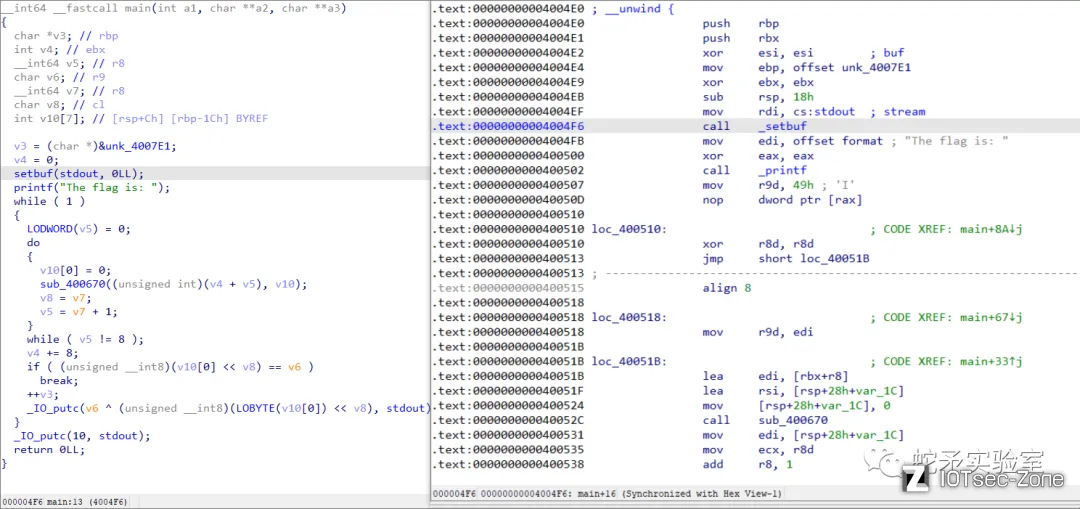
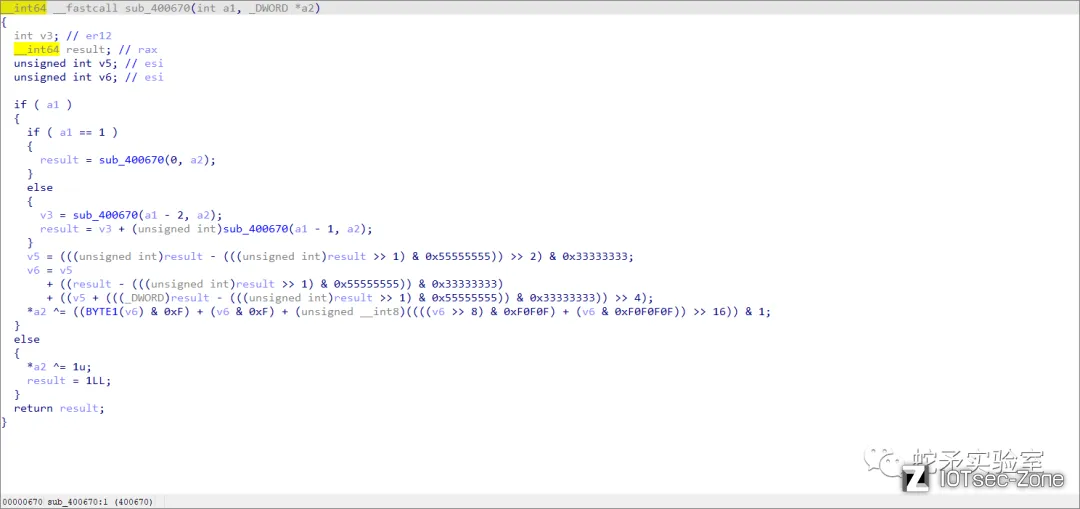
sub_400670函数为加密函数,如果我们基础不够或者并不会逆向,这里便可以使用unicorn仿真执行程序。那么这里unicorn仿真的整体流程就是仿真执行整个main函数,main函数地址为0x4004E0~0x400475。
根据以上我们得出的信息,对模板脚本进行修改:
from unicorn import *
from unicorn.x86_const import *
# 定义要执行的指令
def read(name):
with open(name,"rb") as f:
return f.read()
# 指定内存地址
BASE_ADDRESS = 0x400000
STACK_ADDR = 0x0
STACK_SIZE = 1024*1024
# 定义hook函数
def hook_code(uc, address, size, user_data):
print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' %(address, size))
# 初始化 Unicorn 引擎和内存空间
mu = Uc (UC_ARCH_X86, UC_MODE_64)
mu.mem_map(BASE_ADDRESS, 1024*1024)
mu.mem_map(STACK_ADDR, STACK_SIZE)
# 设置 RIP 和 RSP
mu.mem_write(BASE_ADDRESS, read("./test"))
mu.reg_write(UC_X86_REG_RSP, STACK_ADDR + STACK_SIZE - 1)
# 注册hook函数
mu.hook_add(UC_HOOK_CODE, hook_code)
# 开始模拟执行
mu.emu_start(0x00000000004004E0, 0x0000000000400575)
运行发现在地址0x4004ef处的指令在运行时报错了。unicorn显示Invalid memory read,猜测为地址读取问题。
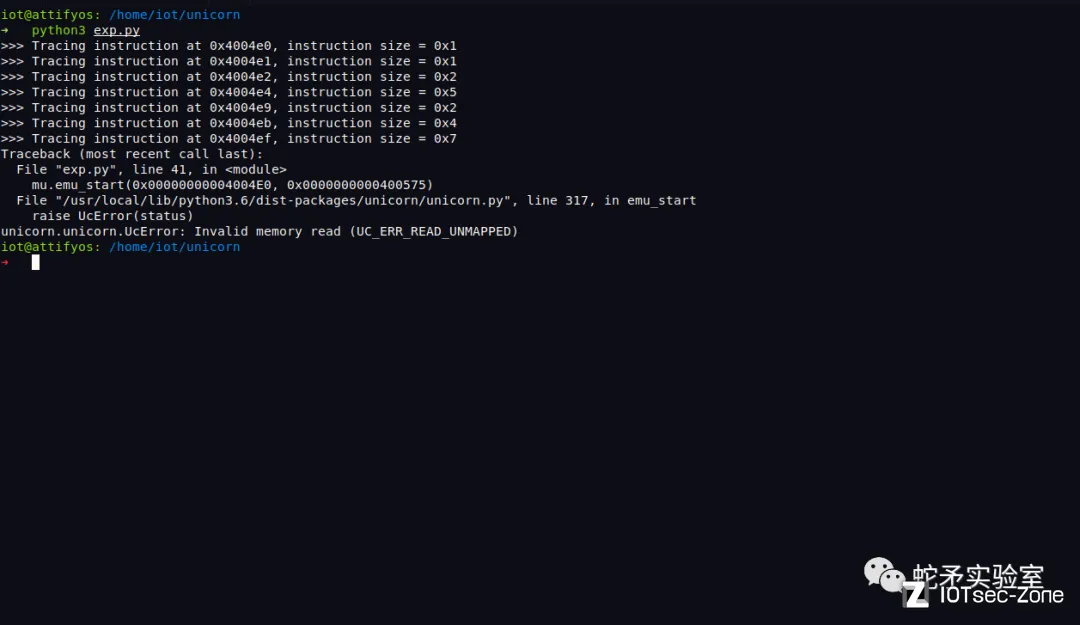
逆向代码发现,报错处的指令为将mov rdi, cs:stdout,原因是由于没有设置cs寄存器以及stdout stream地址导致无法访问。但是这条指令对我们仿真结果没有影响,我们可以手动对程序报错地址0x4004ef处的指令进行patch,使其跳过。patch好以后,再次运行发现又报错了。
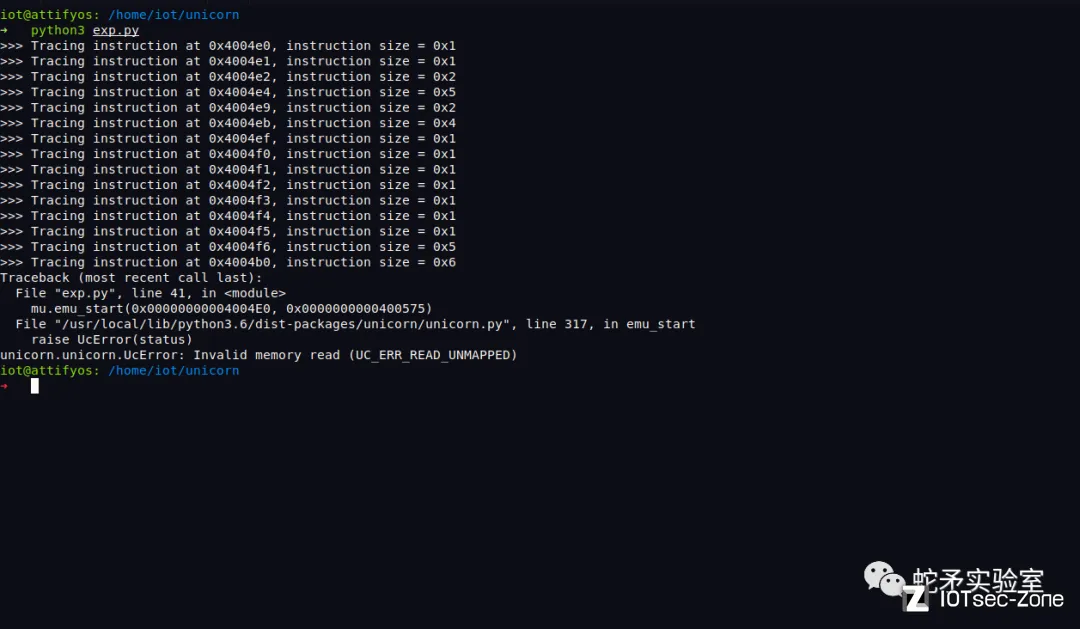
逆向发现,此处和上面形成原因类似,访问了没有设置bss段地址,并且也对仿真结果没有影响。循环往复patch并运行后发现在0x4004EF,0x4004F6,0x400502,0x40054F 地址处都会报错。
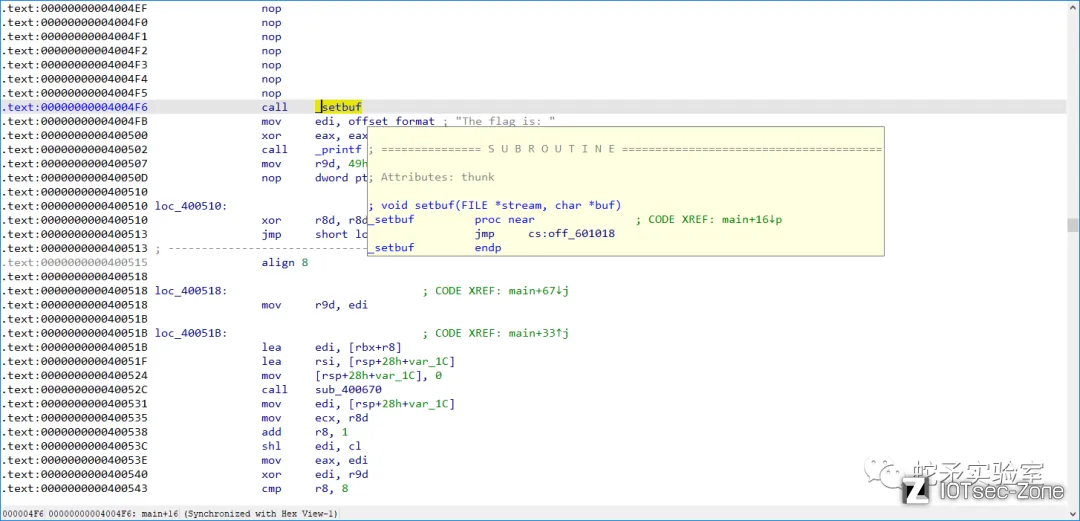
针对于以上遇到的问题的出现并没有对结果产生影响,我们可以在代码中手动过滤这些地址,使其跳过。随后在程序执行最后put函数,我们可以取出打印结果。脚本中添加代码如下:
nop_address = [0x00000000004004EF, 0x00000000004004F6, 0x0000000000400502, 0x000000000040054F]
def hook_code(mu, address, size, user_data):
if address in nop_address:
mu.reg_write(UC_X86_REG_RIP, address+size)
elif address == 0x400560:
c = mu.reg_read(UC_X86_REG_RDI)
print(chr(c))
mu.reg_write(UC_X86_REG_RIP, address+size)
运行脚本后,我们已经可以让程序在运行解密过程了。但是速度极慢,5分钟打印3个字符。

在调试过程中我们发现在运行sub_400670函数时,程序内部条件分支会不断调用函数自身,从而进入递归状态,导致解密时间非常长。我们想到在参数一致的情况下,重复执行sub_400670函数非常占用资源和时间,这里对其进行优化。思路如下,我们可以使用栈空间来保存一个不同输入参数以及对应计算结果的字典来避免重复计算。具体可分为参数保存和返回值取出俩个步骤:
参数保存步骤为:当程序运行到 sub_400670 函数时,会读取函数的两个输入参数(x86_64架构中俩个参数分别保存在rdi和rsi寄存器中),将(arg0, arg1)保存一下。然后,我们检查字典中是否包含这个元组作为键的条目。如果存在,说明之前已经计算过这个函数,可以直接从字典中取出对应的计算结果并执行ret进行返回。如果不存在,则说明对应参数的函数还没有被计算过,程序需要进行函数运算。返回值取出的步骤为:当我们将输入参数压入一个栈中,程序执行完成后,会执行到到函数的结尾处(ret),我们可以在此处取出函数的返回值,并将其存储在 (ret_rax, ret_ref) 中(ret_rax 是函数返回值,ret_ref 是保存返回值的地址)。然后,我们将这个元组作为值,将 (arg0, arg1) 作为键,将其存储到字典 d 中。这样,下一次计算相同参数的sub_400670函数时,就可以直接从字典中取出对应的计算结果,而无需再次进行计算。
在原来的脚本之上,我们添加的代码如下:
from pwn import *
stack = []
direct = {}
ENTRY = [0x0000000000400670]
END = [0x00000000004006F1, 0x0000000000400709]
def hook_code(mu, address, size, user_data):
if address in ENTRY:
arg0 = mu.reg_read(UC_X86_REG_RDI)
r_rsi = mu.reg_read(UC_X86_REG_RSI)
arg1 = u32(mu.mem_read(r_rsi, 4))
if (arg0,arg1) in direct:
(ret_rax, ret_ref) = direct[(arg0,arg1)]
mu.reg_write(UC_X86_REG_RAX, ret_rax)
mu.mem_write(r_rsi, p32(ret_ref))
mu.reg_write(UC_X86_REG_RIP, 0x400582)
else:
stack.append((arg0,arg1,r_rsi))
elif address in END:
(arg0, arg1, r_rsi) = stack.pop()
ret_rax = mu.reg_read(UC_X86_REG_RAX)
ret_ref = u32(mu.mem_read(r_rsi,4))
direct[(arg0, arg1)]=(ret_rax, ret_ref)
此时再次运行脚本,爆破速度提升,且运行结果已经完全显示。

unicorn也固件解密中也发挥了重要作用,在文章(https://www.shielder.com/blog/2022/03/reversing-embedded-device-bootloader-u-boot-p.2)中,作者通过对某华设备固件进行逆向分析以及unicorn仿真执行解密出了kernel文件。大致思路如下,作者通过binwalk提取固件,发现固件已经被加密,并对提取出来的部分进行分析后发现uboot.bin具有可利用信息。
对uboot.bin进行逆向分析后,通过开源uboot代码恢复符号表,定位出了uboot解密kernel时的对应加密函数。
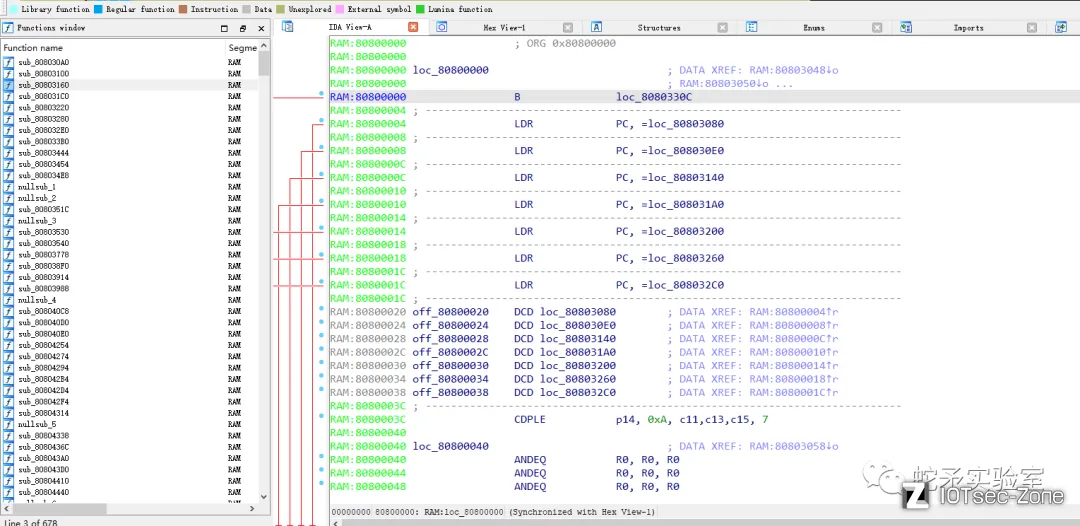
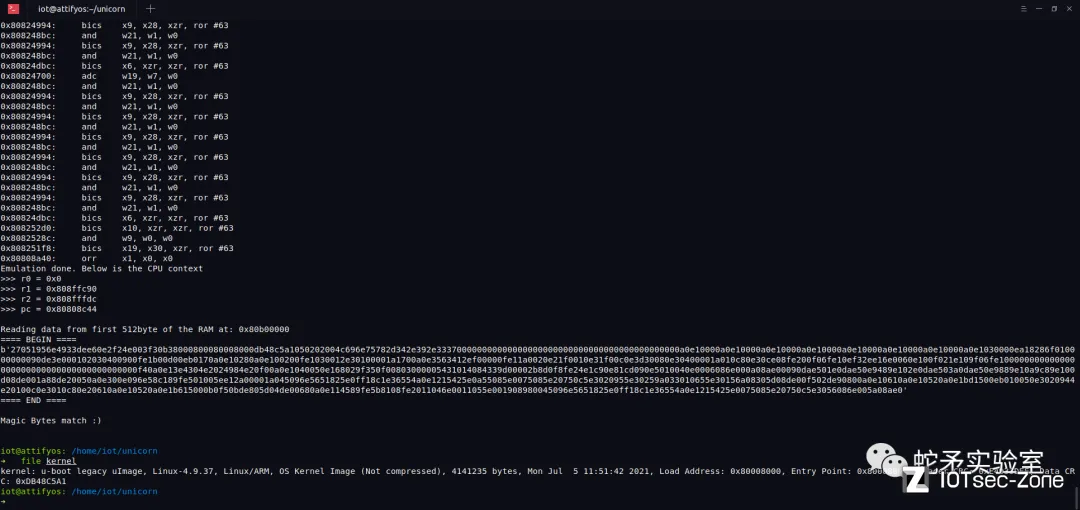
在解密算法时发现uboot载入kernel.img并对其进行AES解密。解密共有俩种方法,一种方法为逆向解密,需要一定的逆向技术才可完成,较复杂。另一种方式便是使用unicorn仿真执行解密函数,该种方法较为简单便捷。这里选取了第二种方式来解密,核心代码如下,代码使用 unicorn 待解密文件加载到虚拟内存并执行模拟执行解密代码 ,并使用disas_single函数打印出此时正在执行的汇编指令来便于我们调试。
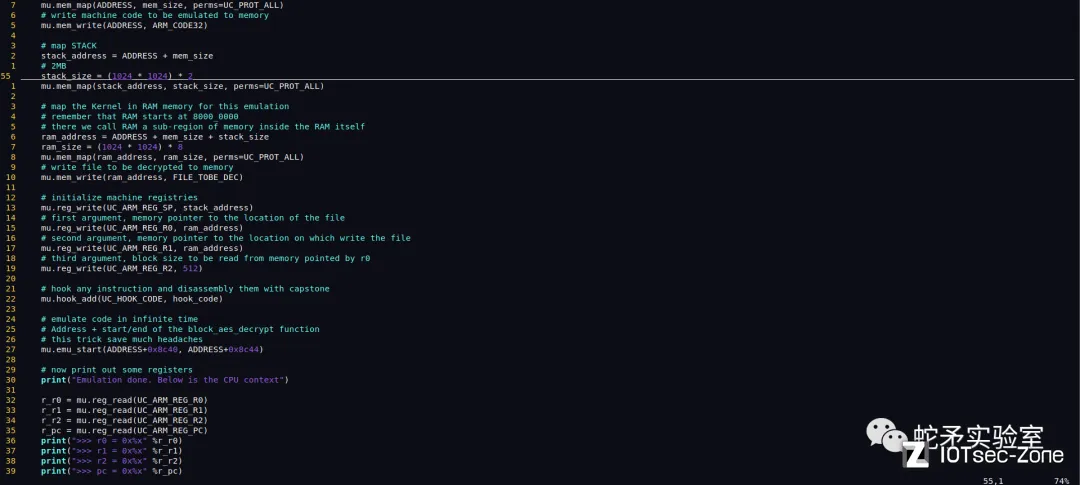
执行后便解密出了vmlinux前512字节,完善脚本后便可解密整个vmlinux文件。随后,我们可以使用vmlinux-to-elf工具对vmlinux恢复函数符号表。一般情况下,linux下对固件升级和固件加密都是放在内核完成的,接下来我们对kernel文件进行逆向分析就可能得出rootfs的解密流程。
unicorn除了在ctf和固件解密方向有实质性作用,在漏洞挖掘的fuzz方向也具有一定研究价值,但是基于unicorn的fuzzer较为复杂且难度较高。与此同时,qiling框架的出现使得仿真fuzz变得较为简单。qiling是一个基于unicorn引擎开发的高级框架,它可以利用unicorn来模拟CPU指令,但是它同样可以理解操作系统上下文,它集成了可执行文件格式加载器、动态链接、系统调用和I/O处理器。更重要的是,qiling可以在不需要原生操作系统的环境下运行可执行文件源码。现阶段来看qiling框架更加适合安全研究人员,这也是我们后面需要学习的内容。
总结
这一小节,我们学习了unicorn框架的使用基础,并通过一道ctf题目仿真并解出了flag。同时学习了unicorn在固件解密方向的思路,使我们更加了解unicorn框架。


