前言
VxWorks以其良好的可靠性和卓越的实时性被广泛地应用在通信、军事、航空、航天等高精尖技术及实时性要求极高的领域中,如卫星通讯、军事演习、弹道制导、飞机导航等。
遇到好几次Vxworks固件了,真是每次被拷打每次都有新的一点感悟,从不知所措到稍微知道怎么做了
符号表缺失其实可以根据字符串的提示、静态编译的库函数的辨别去硬逆个大概,甚至有些残存符号表可以仔细找找恢复上去,
但如果是遇到某些路由函数,就可能没有办法——没办法去看路由到的文件,有时候就不能很好地分析整个数据流
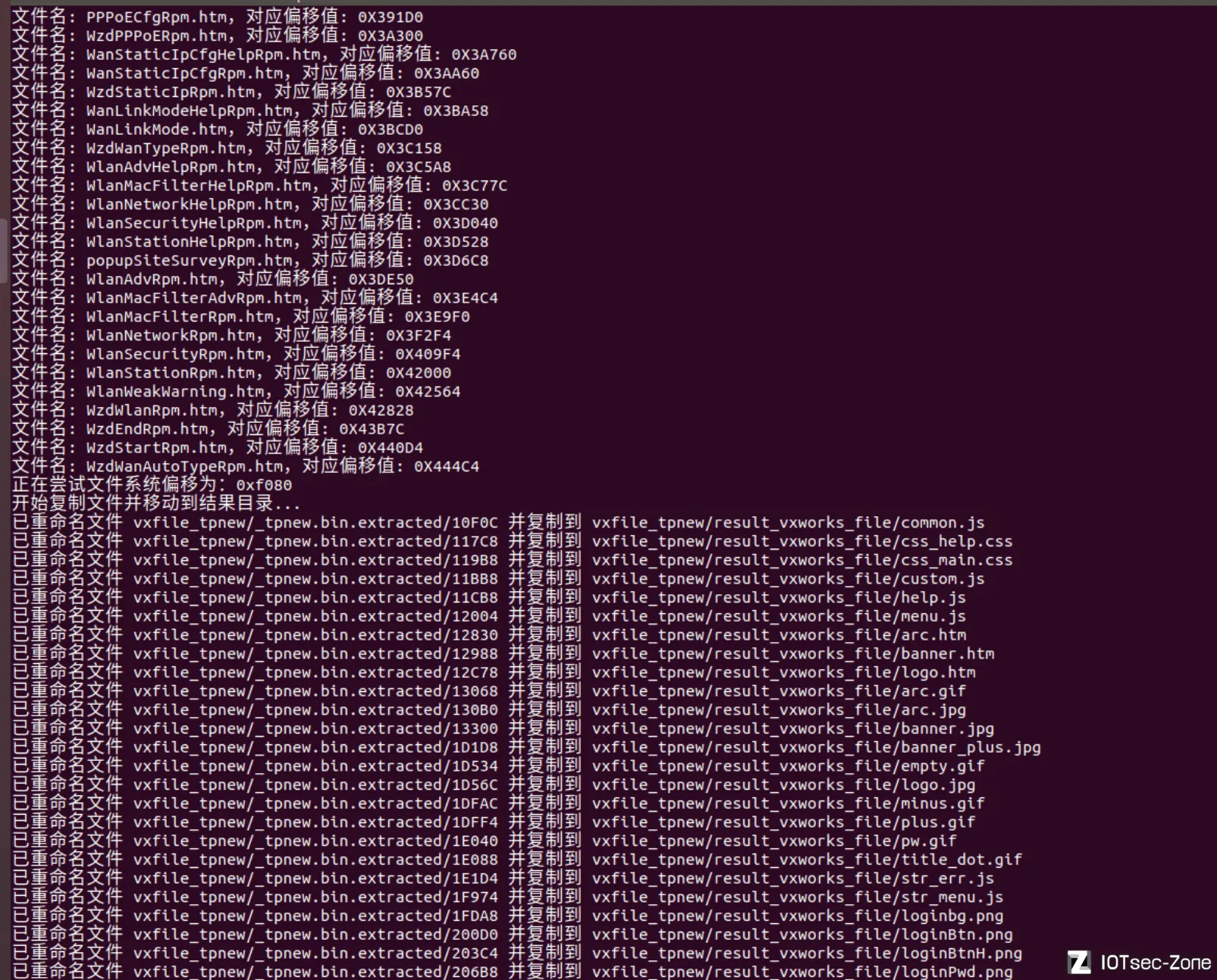
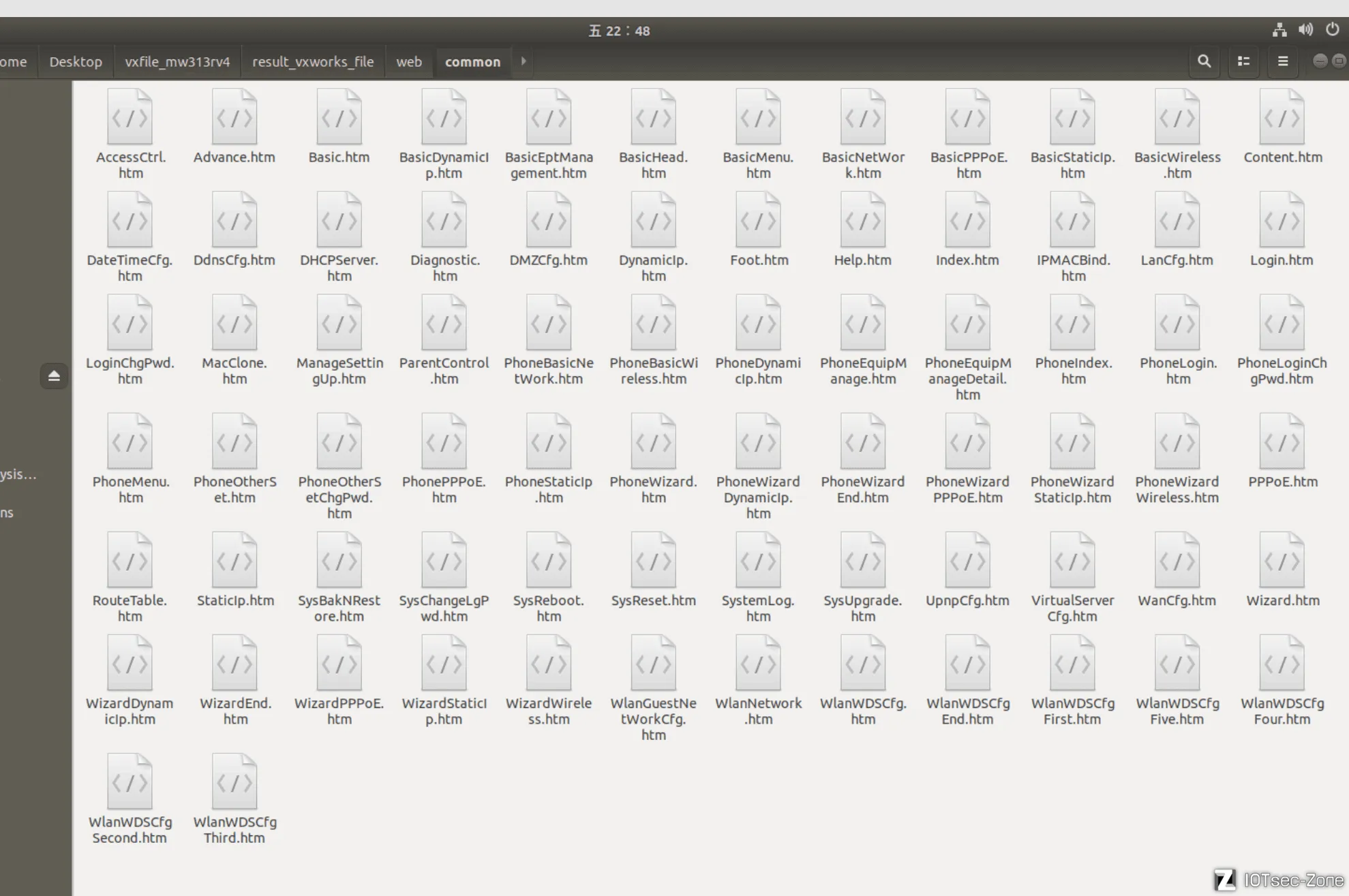
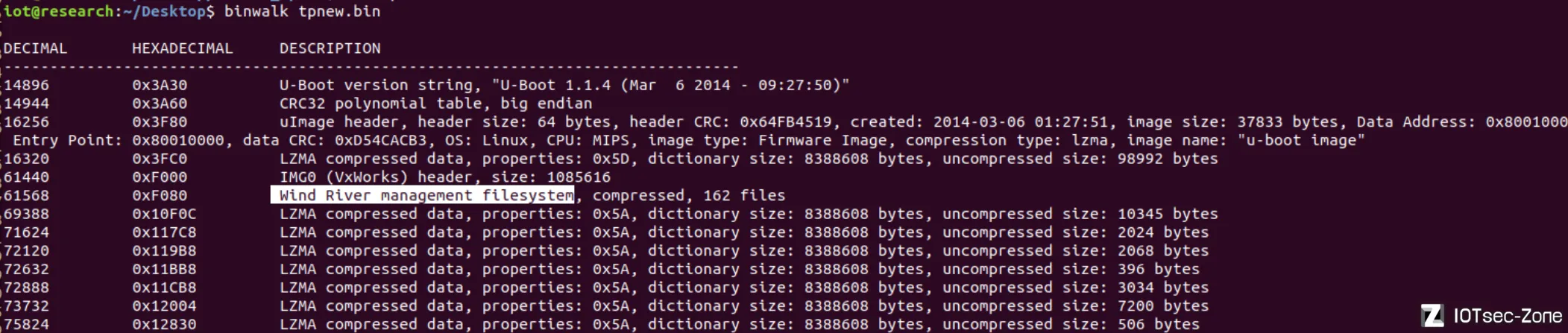
因为,binwalk一把梭vxworks固件出来的画风往往是这样的,命名非常的混乱,但如果实际打开看看,内部内容其实是正常的
仔细一想,vxworks系统启动的时候,肯定是有什么参照去恢复文件名和位置的,否则怎么做路由呢
所以就开始了接下来的vxworks文件名恢复探究,以及,一键自动化
寻找偏移表和文件命名
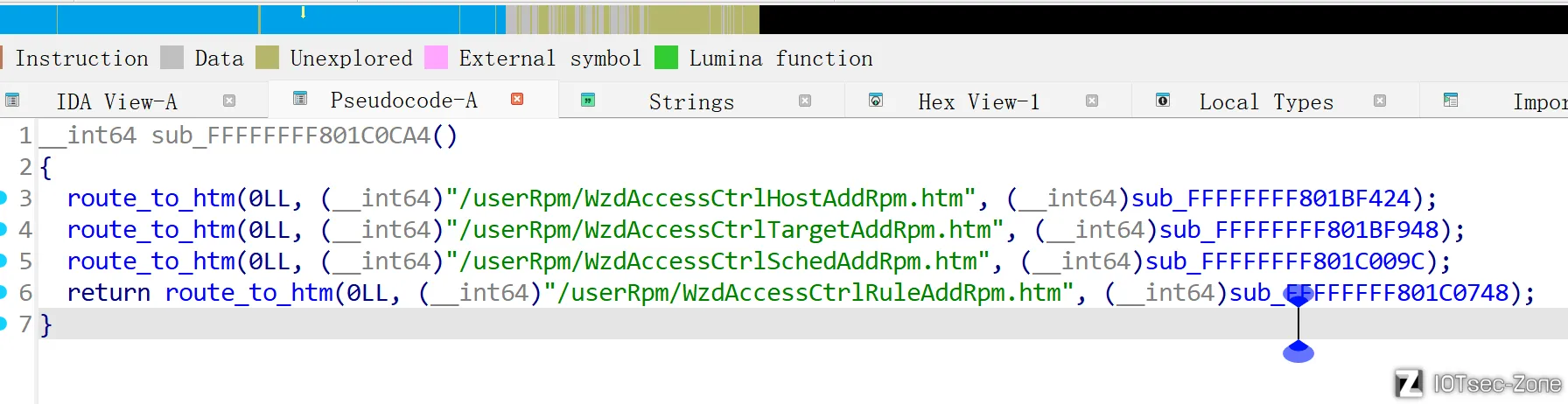
既然要恢复文件名,反过来就可以grep一下文件名去找这个表。以上图第二个例子为例
/userRpm/WzdAccessCtrlTargetAddRpm.htm
grep -r "WzdAccessCtrlTargetAddRpm.htm"可以得到这几条结果:

可以看到有两个别的文件(实际上也是htm文件)定义了表单,提交数据到WzdAccessCtrlTargetAddRpm.htm
只可惜我们连这两个htm叫什么名称都不知道,这就很难去分析数据流了
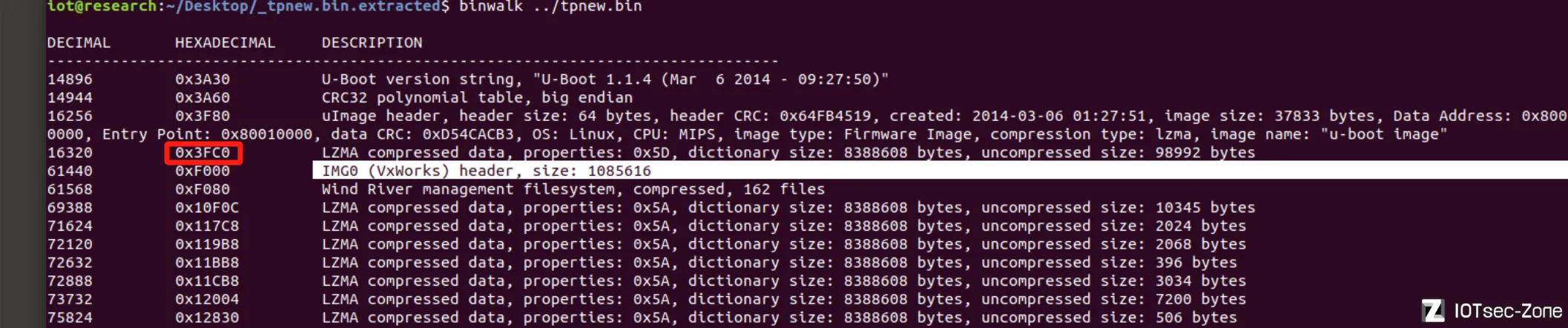
说回正题,有两个文件引用了这个htm,分别是0x3FC0和0x53D60处分割出来的文件,以各自在固件中的偏移来命名(3FC0、53D60)
实际上这两个文件是有来由的
3FC0其实就是uImage镜像

而0x53D60的大小远远大于其它LZMA压缩区域,实际上,这正是vxworks的主程序bin文件,也是我们平常分析的重点文件

所以比较合理的解释是,53D60有这个字符串的原因是在web服务时进行路由
而3FC0(uImage)作为vxworks的启动镜像,其拥有这个字符串的唯一原因,是在恢复文件名和结构什么的,所以,如果有偏移表,那就在uImage内部。把3FC0放入010editor看看:
首先,是最初的引导部分,这里放的都是程序代码:
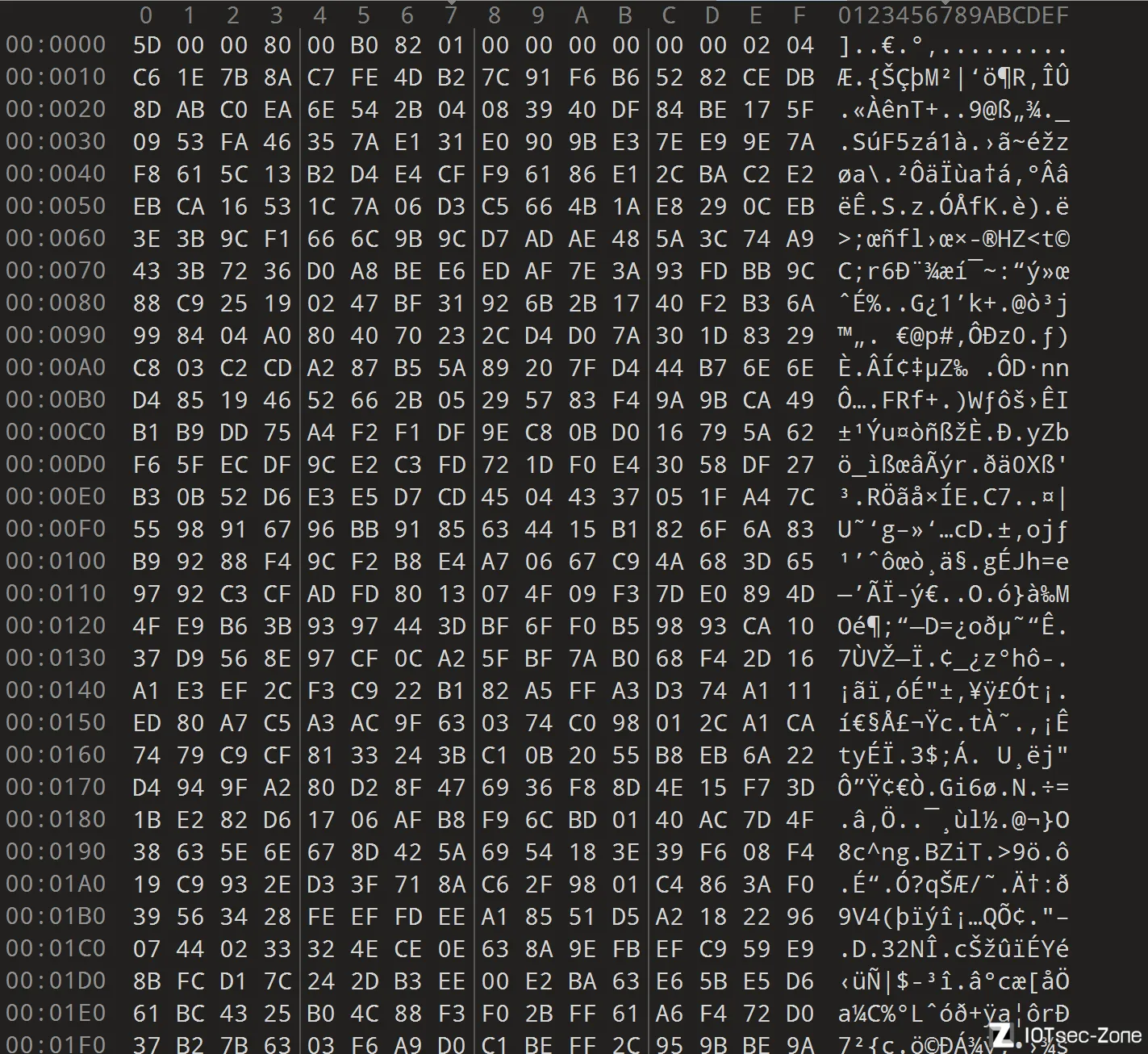
搜索".htm"或者".png"之类的字符串,就能找到一个很整齐的表
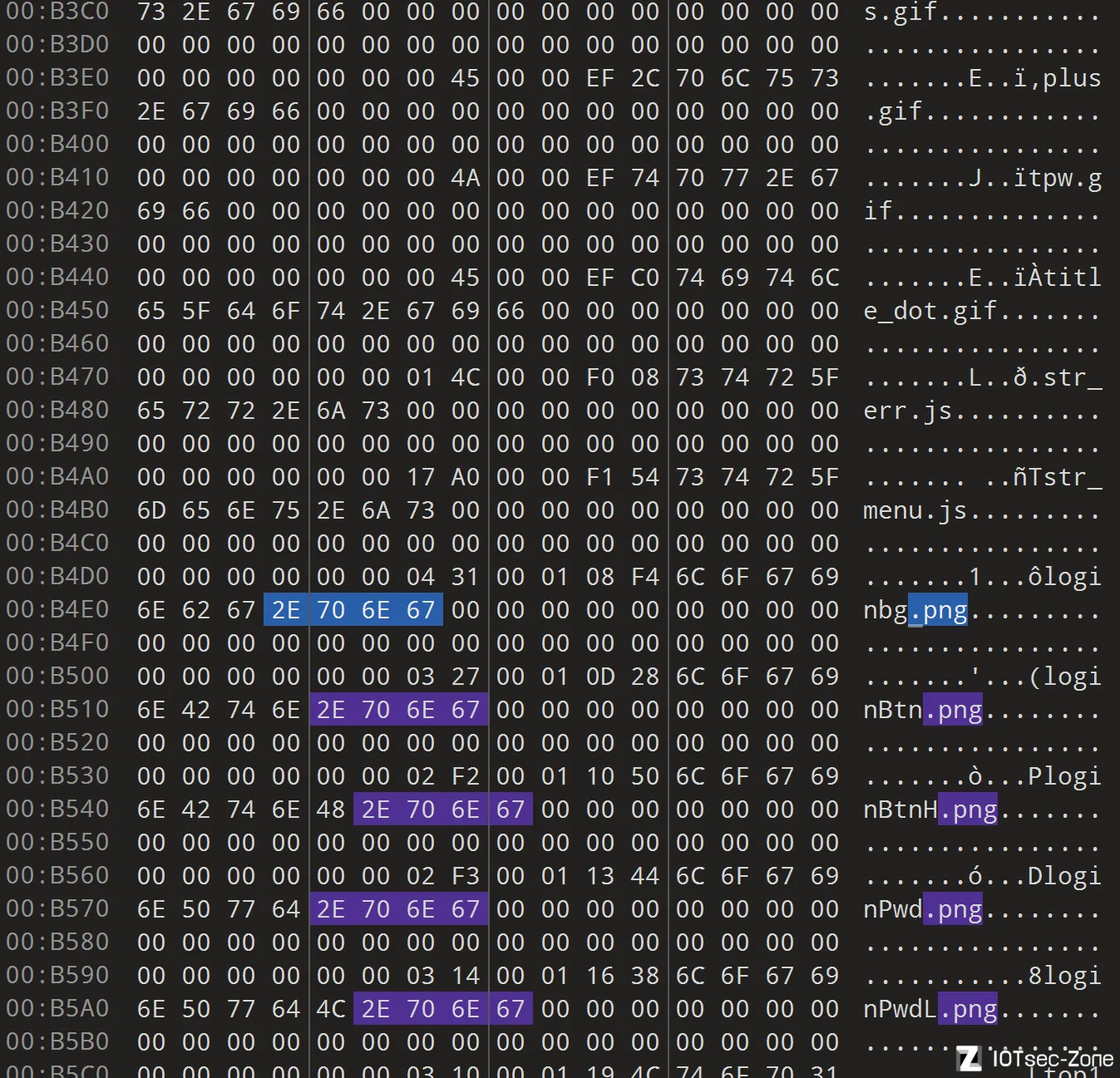
可以看到文件名的前面,好像有类似于偏移的记载,不过到目前还是猜测
如果能找到一套正确的计算方法,能完全对上binwalk里面跑出来的镜像偏移的话,那就说明这确实可以用来恢复文件名
至此,我们找到了最关键的表项,而具体的细节还需探究一下
确认文件名与偏移量的对应关系
偏移表结构
一个容易踏入的误区是,刚开始以为文件名的前面是其对应大小和偏移,为此计算了十几个,发现不对劲,为什么每种文件总是有1-2个的偏移是别的文件类型,而其它都是对应类型的呢
实际上,文件名的一串00 00 00 00后面,才是它的大小和偏移量
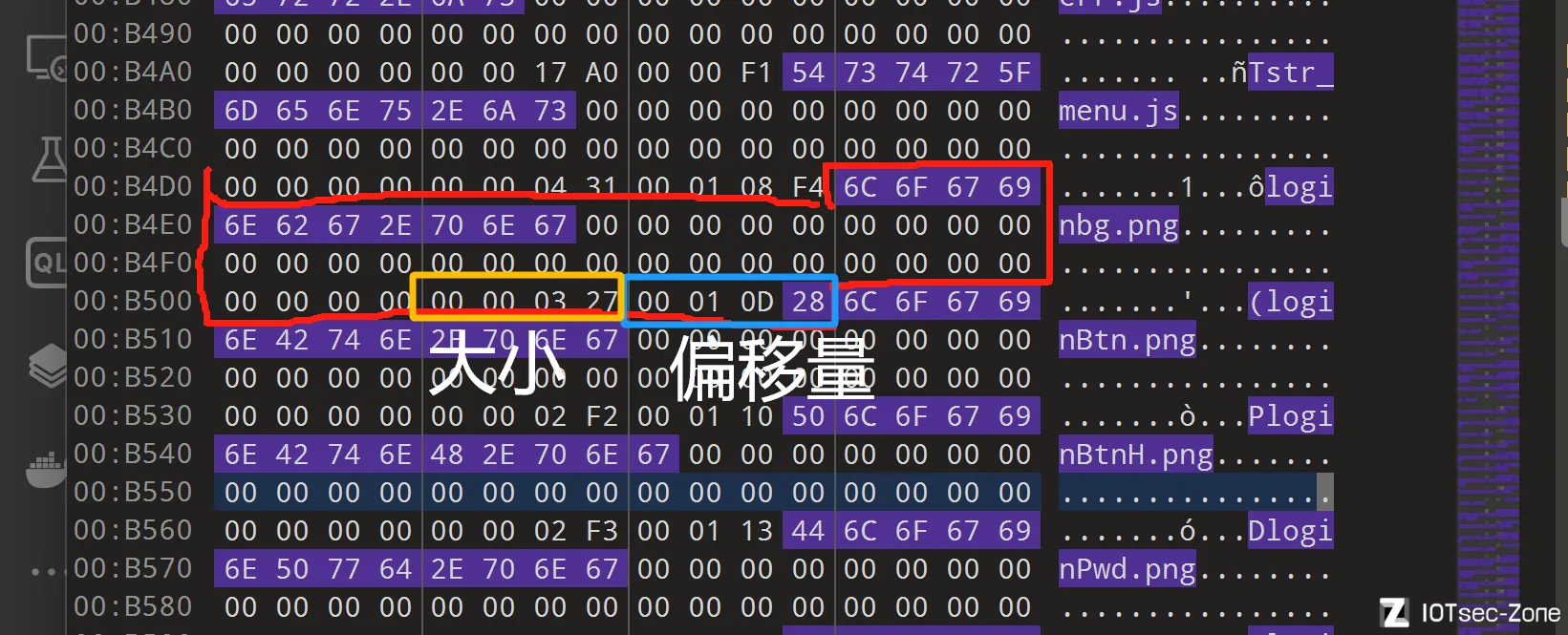
确定文件系统偏移
一些固件,比如这个案例,会记载文件系统的偏移(没记载也可以有兼容性很好的方案,下一节细说)
实际上,表里的偏移量+文件系统的偏移,将会对应到binwalk解包的文件名,即,在固件中的偏移值,这就是vxworks文件名恢复的方法
动手实验:偏移计算
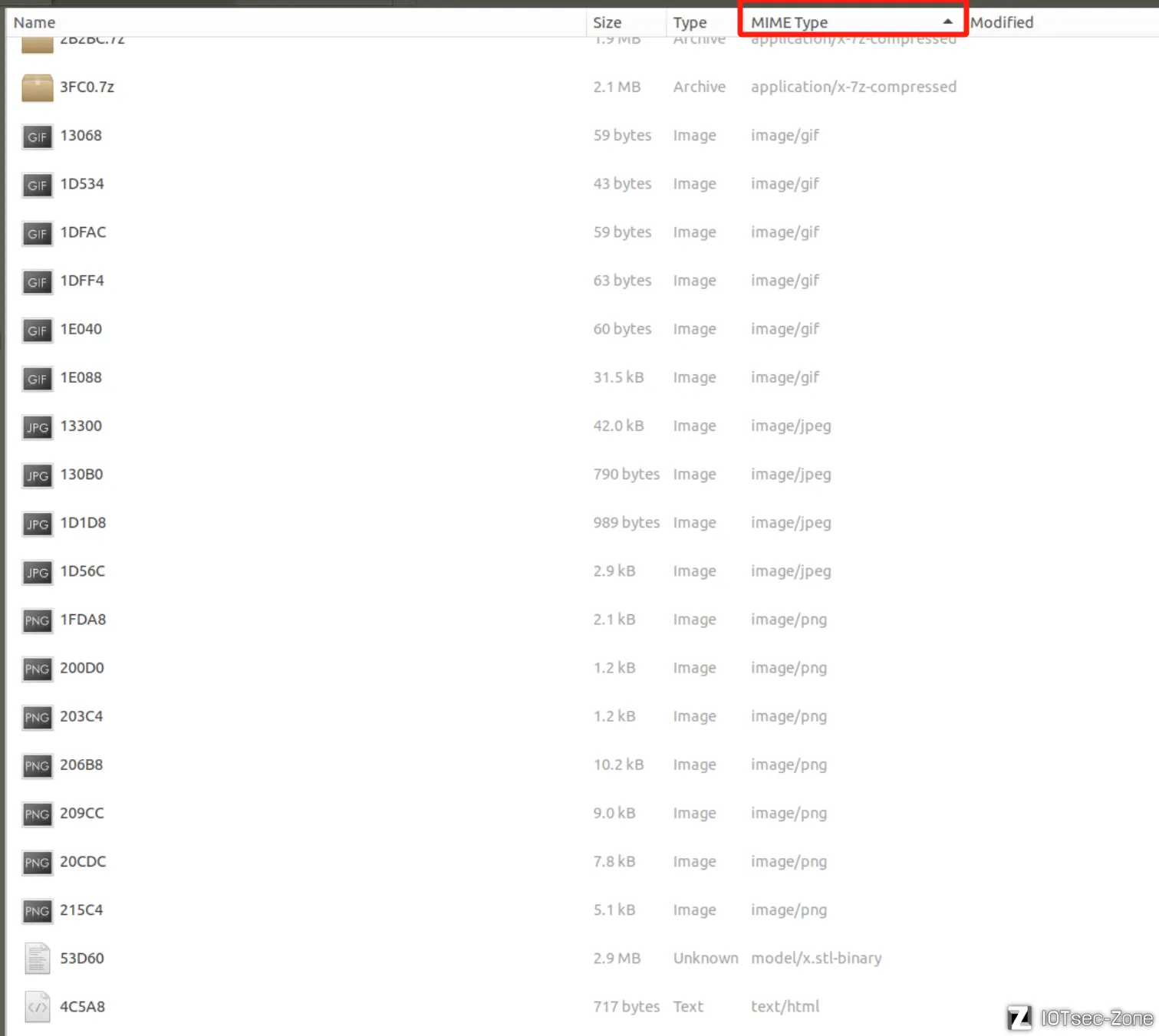
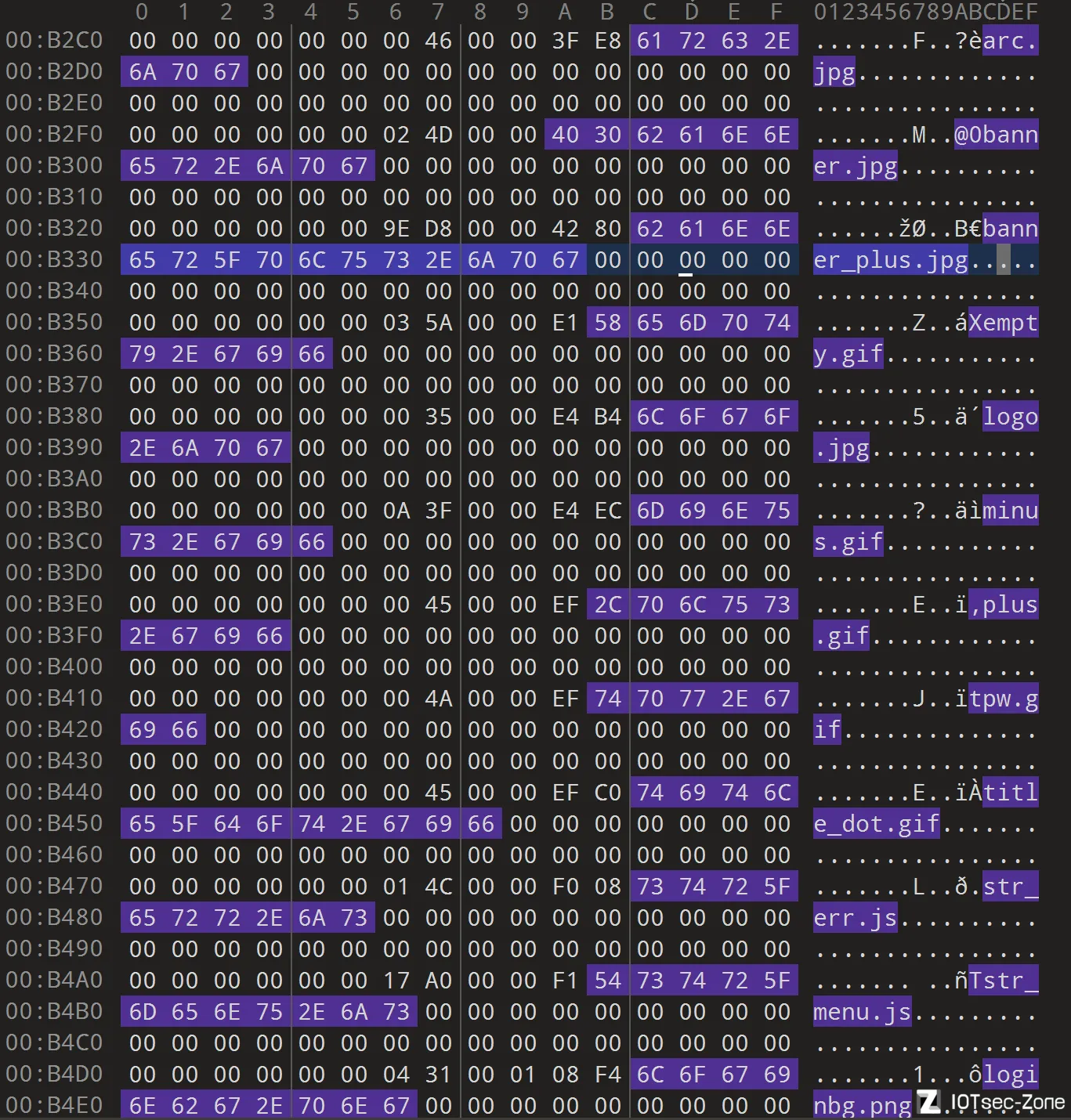
在反复的测试当中,我发现vxworks的文件系统有很多都是文件系统偏移0xF080+xxx的组合。比如,以png来作为测试案例:
首先按MIME type排序一下,因为偏移表本身也是按照类型来集中排布的,这样可以方便实验
然后,以png为例进行偏移量的计算测试
可以在010editor等工具里面找到如下.png字样
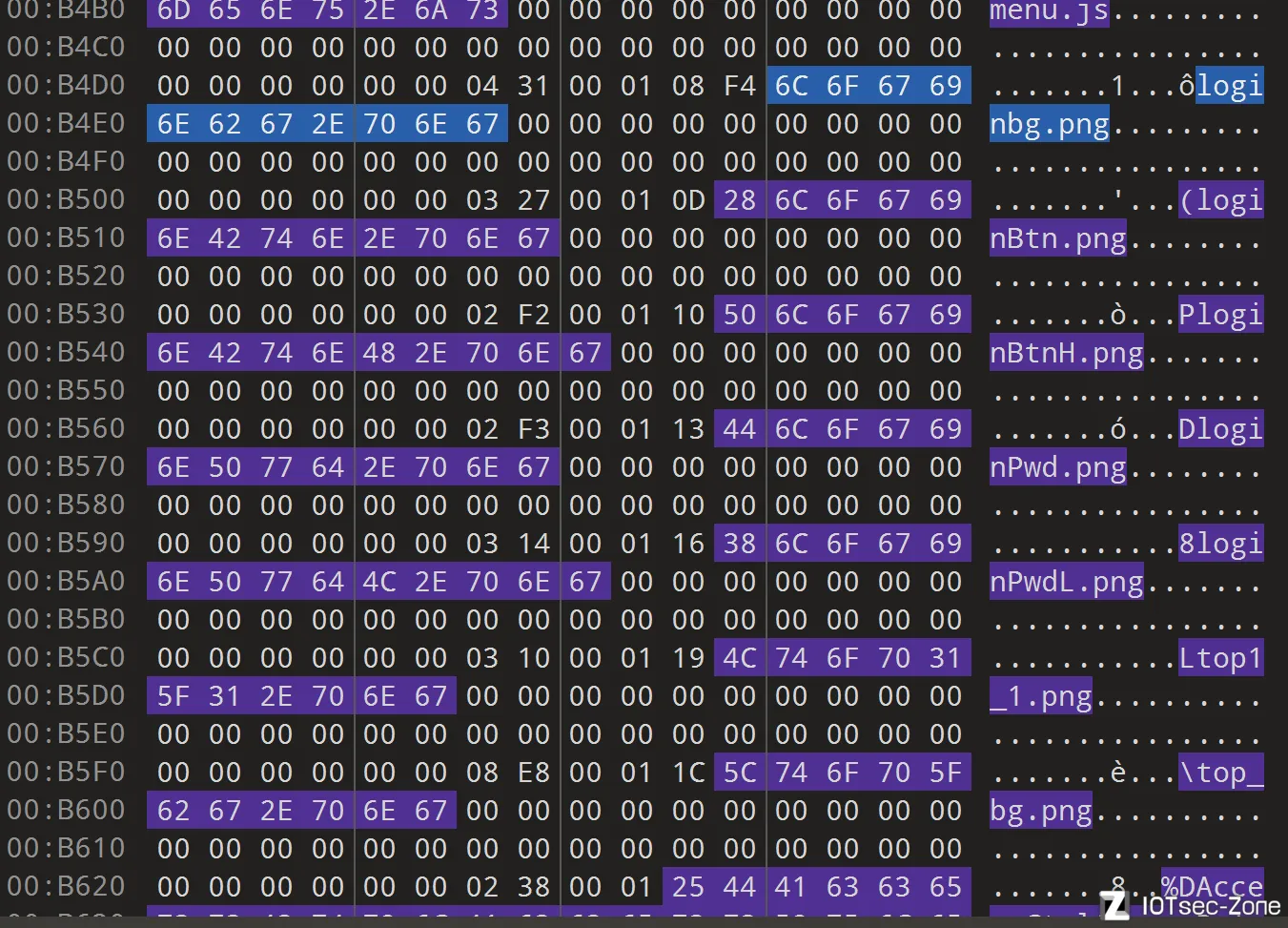
将其偏移逐一取出,并加上刚刚提到的0xF080,我们可以得到一些偏移量:
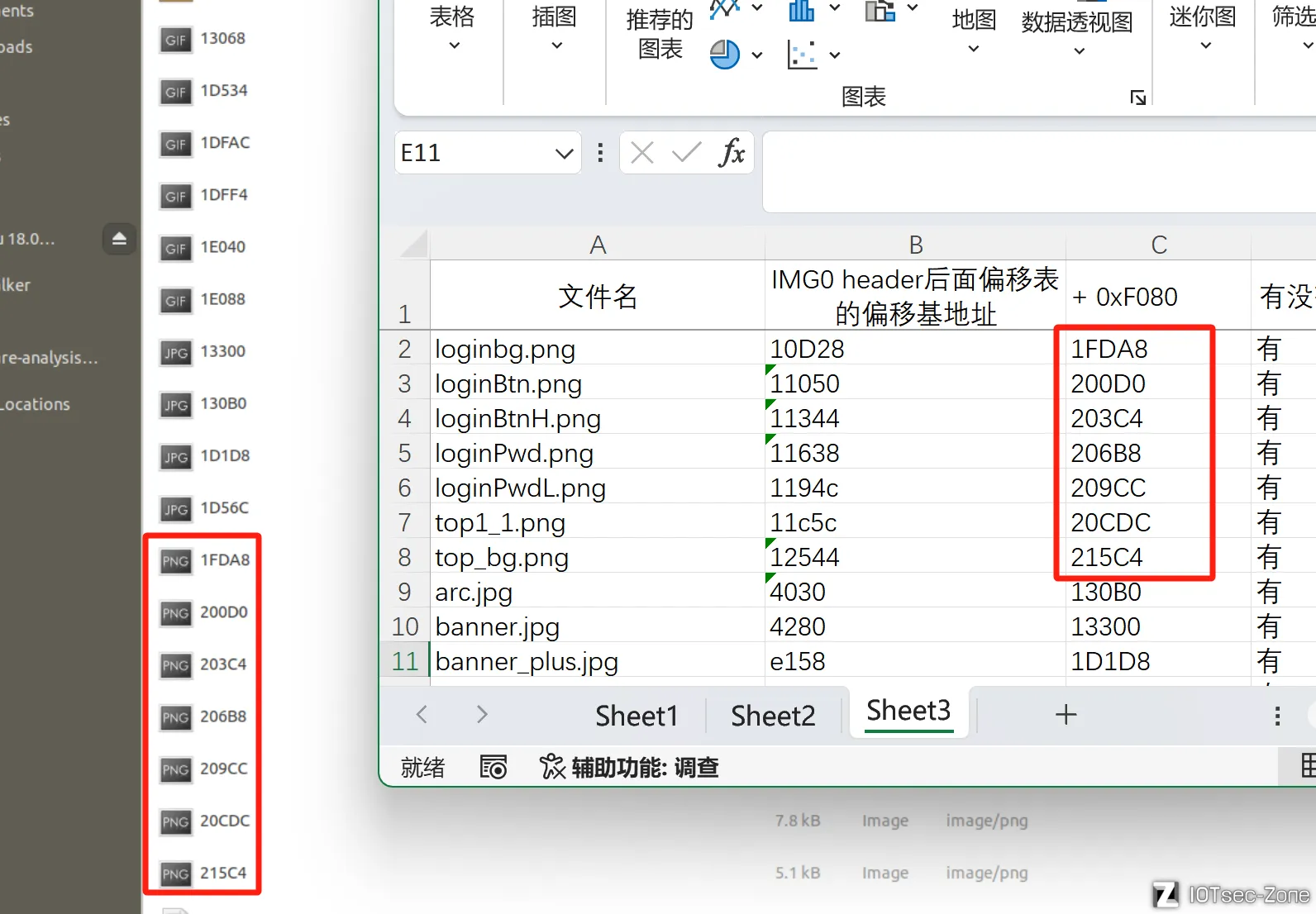
如图所示,所有的文件名都能找到对应偏移,那么,说明这种办法是切实可行的:比如binwalk解析出来的1FDA8,我们就可以知道它其实叫做loginbg.png,等等
(使用的excel语句是=DEC2HEX(HEX2DEC(B2) + HEX2DEC("F080")),可以帮助加快这个测试过程,不用每次都按计算器)
紧接着来测试下jpg、gif,找到偏移表对应表项
实验结果如下
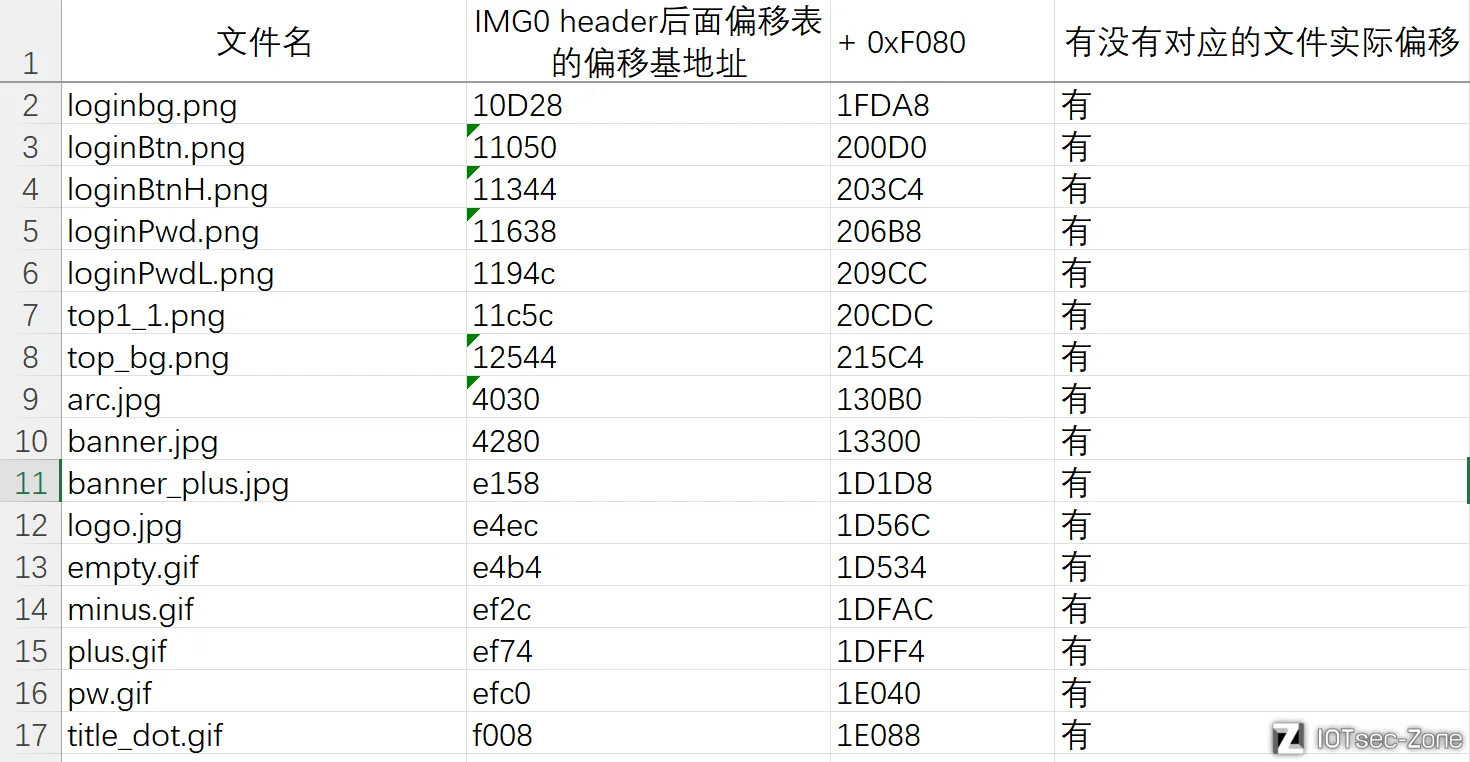

全对,看来该方法是正确的
思考一键自动化VxWorks文件名恢复过程
接下来就是想自动化这个繁杂的过程,就是想能够像binwalk一样一键提取并恢复,而且为了以后反复使用,需要比较可靠的设计
接下来介绍一些比较奇怪的设计的地方,力求更加兼容
基本设计
首先,binwalk的各种文件标签识别还是很厉害的,那就必须使用binwalk的结果了。同时我们需要binwalk -Me一下,以提取所有文件
路径最好和默认的不一样,避免用户在先前的vxworks探索中改动了文件名什么的,导致部分文件找不到对应名称
在binwalk结果里,IMG0 (VxWorks) header前后,将会是很多信息的集中点,其前面是uImage偏移,后面是文件系统,所以会有专门的字符串匹配
如何自动提取文件系统偏移
然后,我们需要读取IMG0 (VxWorks) header后面的那个文件系统偏移地址,
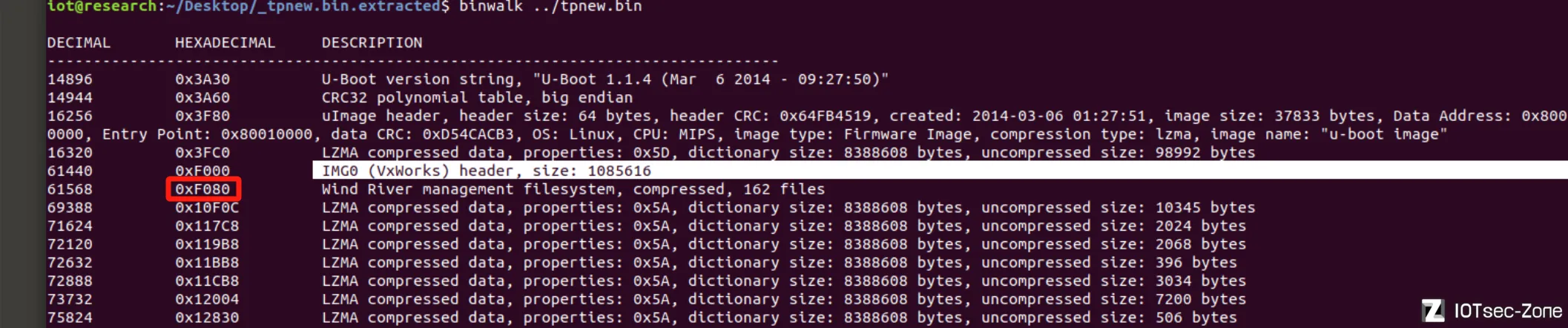
经过实验有些案例里面并非IMG0 (VxWorks) header正下方的偏移,而是下下方的偏移
所以,为了提高脚本的兼容性,设计成了尝试IMG0 (VxWorks) header后三行的偏移量,应该是没有太大兼容问题的
如何自动提取偏移表在uImage镜像位置
再之后,需要从IMG0 (VxWorks) header前面的那个区域,比如这里的0x3FC0,里面存放有我们需要的表
如何全自动确定这个表的位置,以让我们不需要手动打开HxD和010editor去手动给程序这个参数?
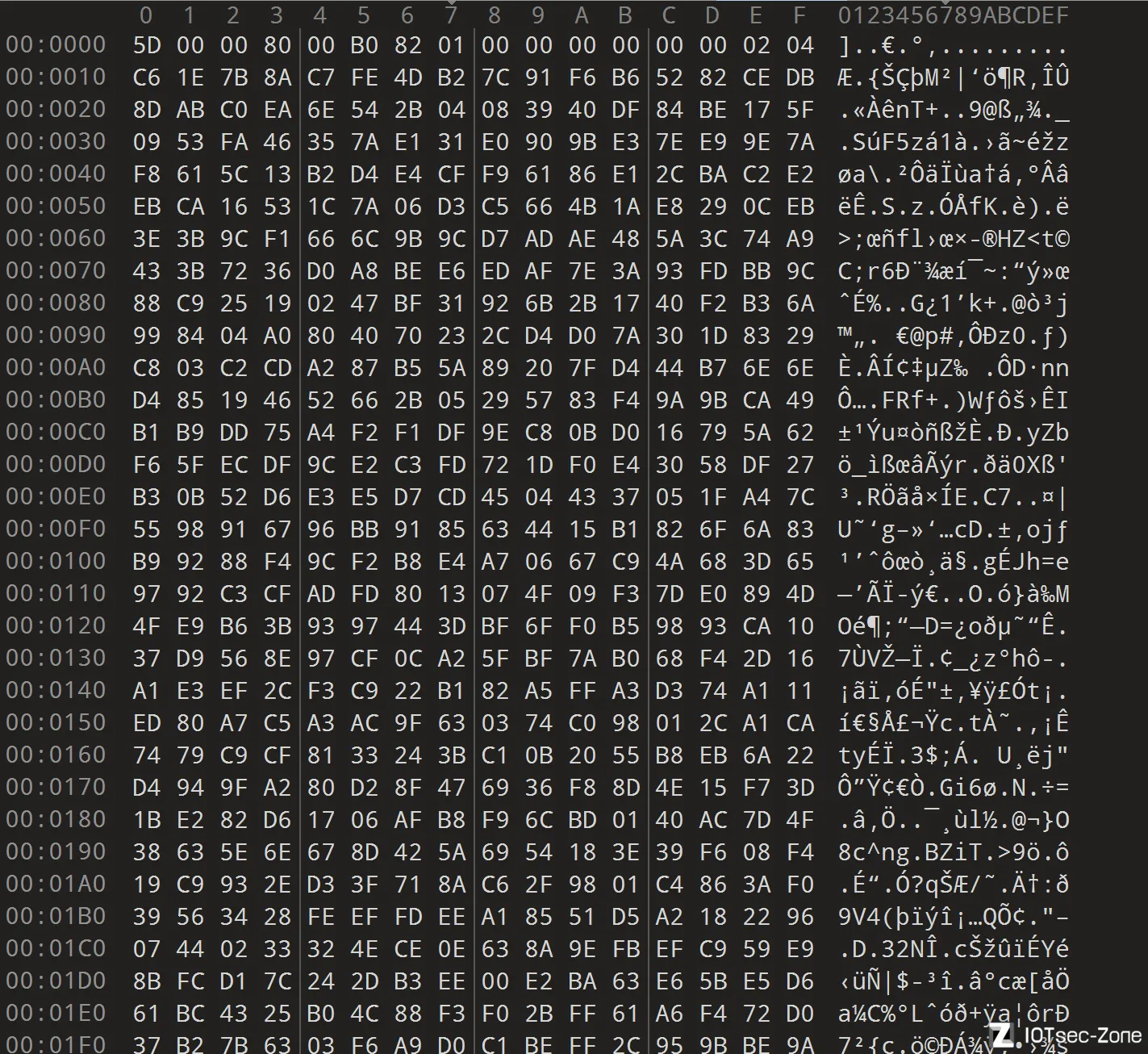
但是问题就来了,如刚才所述,最初的引导部分,这里放的都是程序代码:
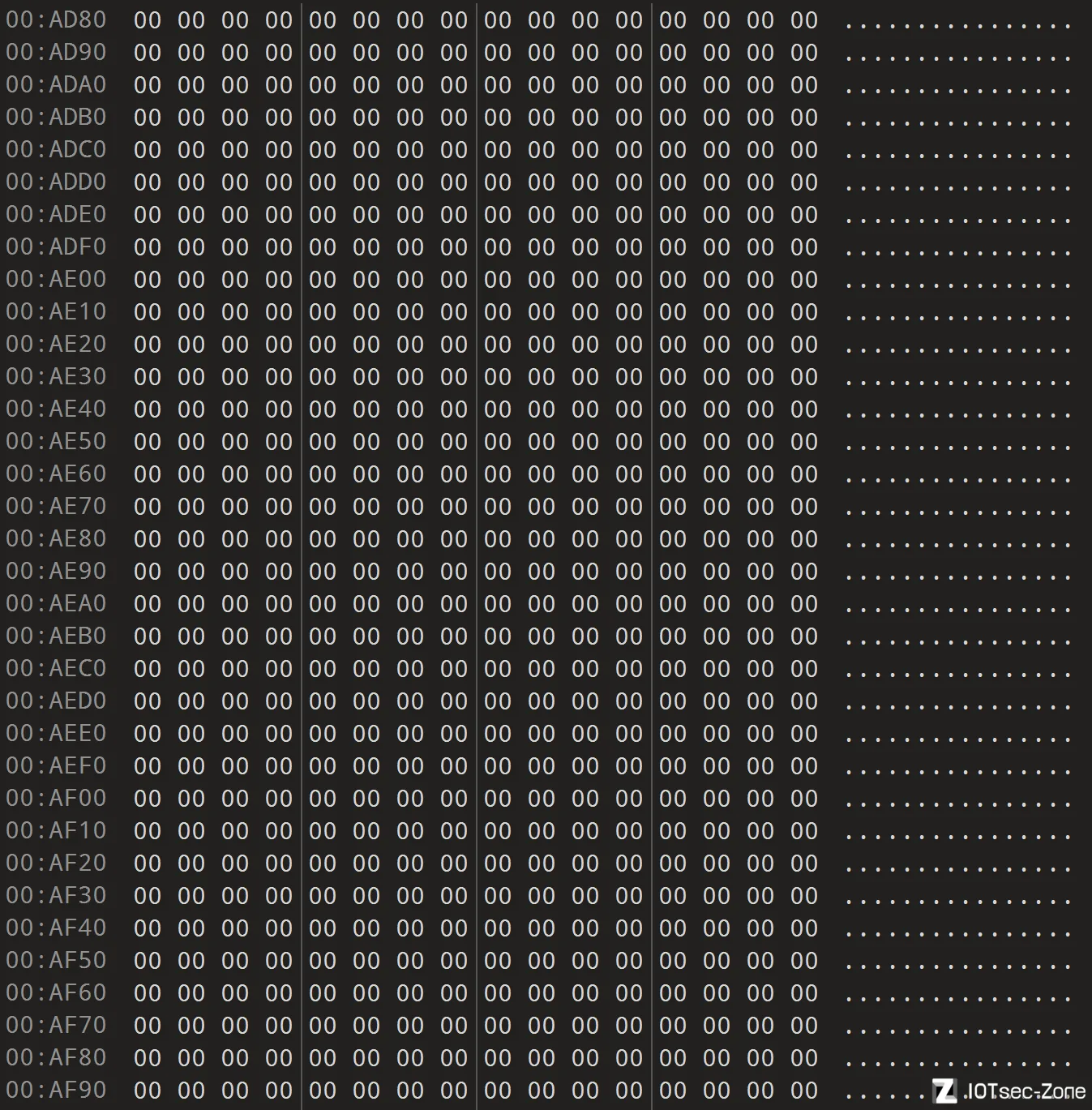
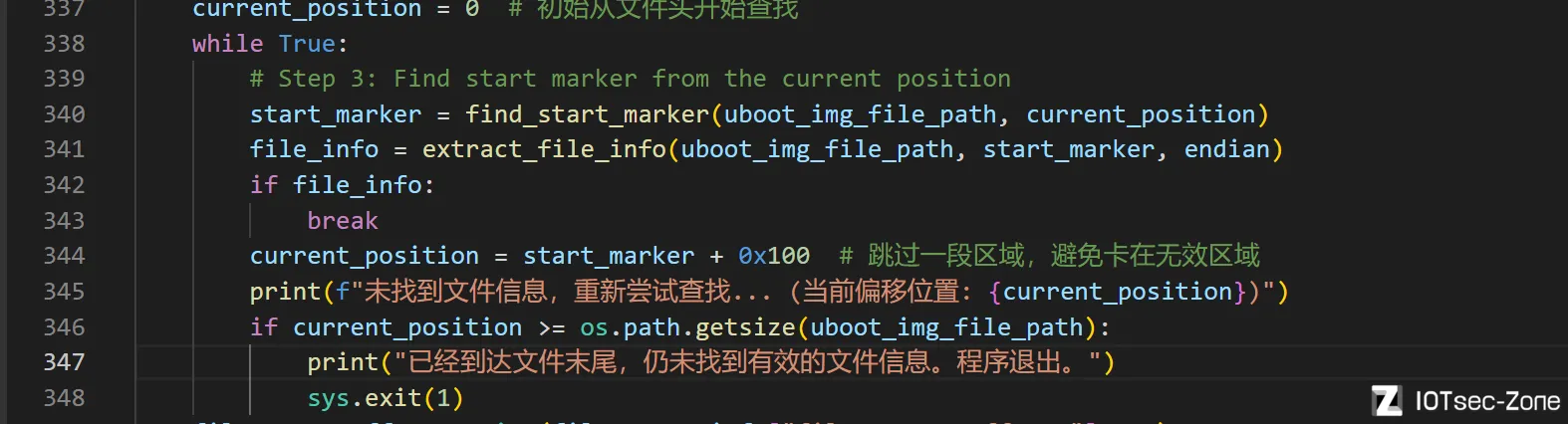
好消息是,在连续的启动引导代码以后,会有大片的00区域,思路是,其实可以进行检测,检测到多少个连续的00,就进入到搜索头部模式;如果检测到又有字符了,那基本上就是我们的IMG0头部了(对...对吗?哦布莱克斯)
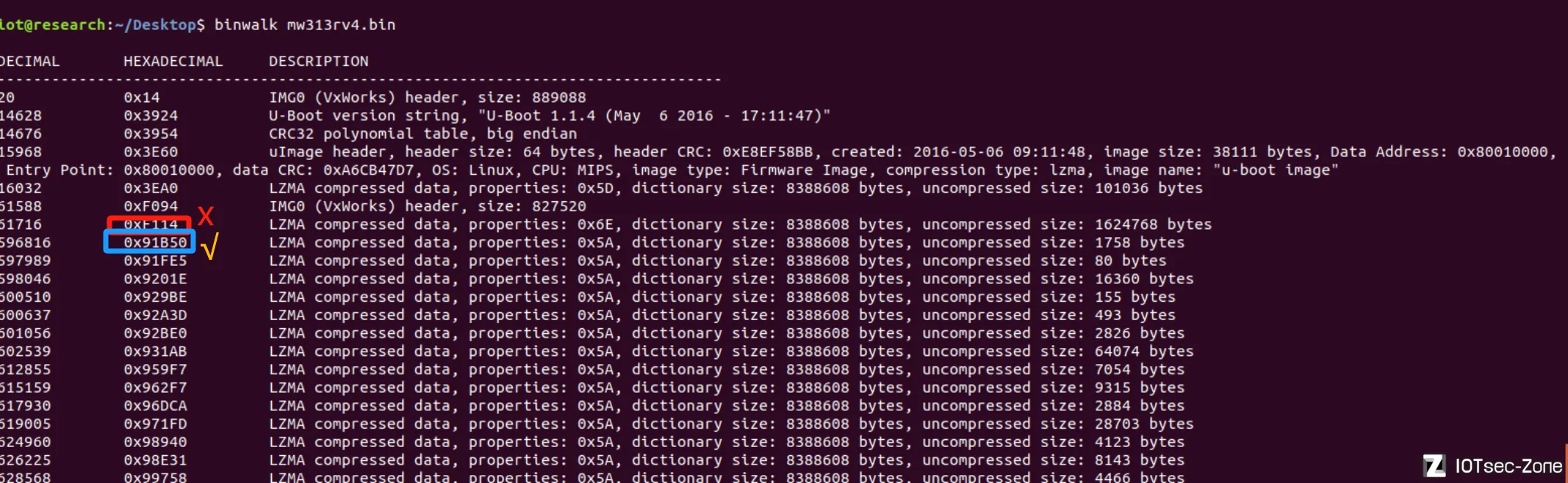
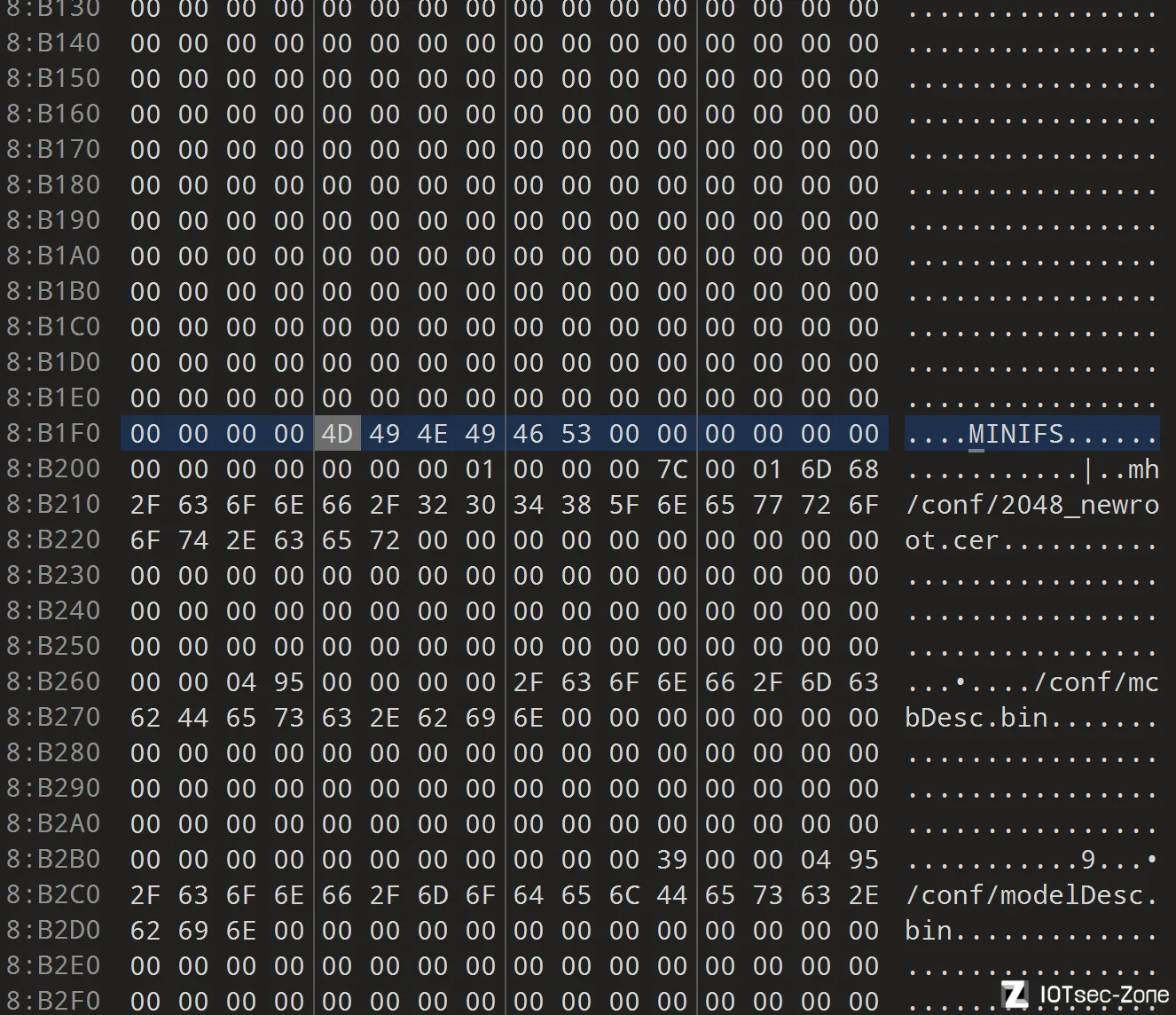
对,也不对,有些固件是有多段引导代码的,
具体表现例子为:
程序片段1+"00 00 00 00"*n+程序片段2+"00 00 00 00"*n+程序片段3+"00 00 00 00"*n+偏移表
那比较简单地一次匹配多次出现的00字节,自然会不对,这样会让程序匹配到程序片段2
比如水星系列mw313r,其该表项藏在3个程序片段之后,0x8b1f0处,这也让我发现需要去兼容这个问题
最后,采取的方案是在使用extract_file_info()函数提取信息时,检测名称的合法性,如果发现提取不了文件名(连续失败到一定的阈值,说明不正常了),那就在提取文件名失败的地方重新开始搜索偏移表
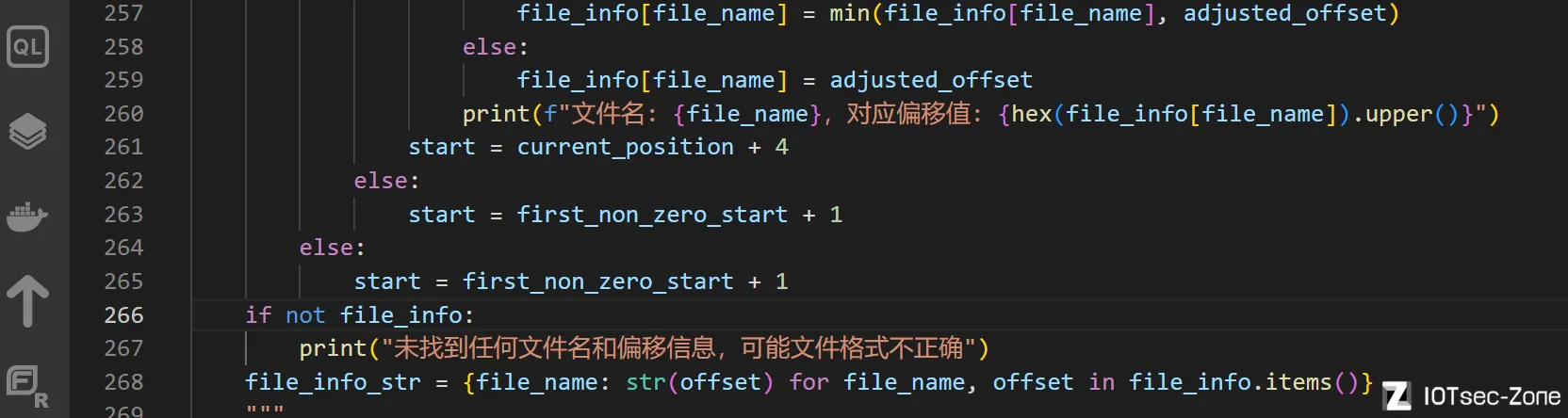
怎么正确识别文件名
正确识别文件名,即一个文件偏移记录块的开端,那么同时就可以解决偏移的提取问题
仅限这些字符命名的文件:大小写字母、数字、下划线、短横线、斜杠,
而且,必须有一个"."符号,因为vxworks目前遇到的,所有的文件都是有后缀的,即便是二进制文件
而且,会按照4字节对齐的方式去取文件名
总之这套正则匹配使得精确程度提高了,比如,下面的owowowow...字符串,等等,就不会被匹配进去
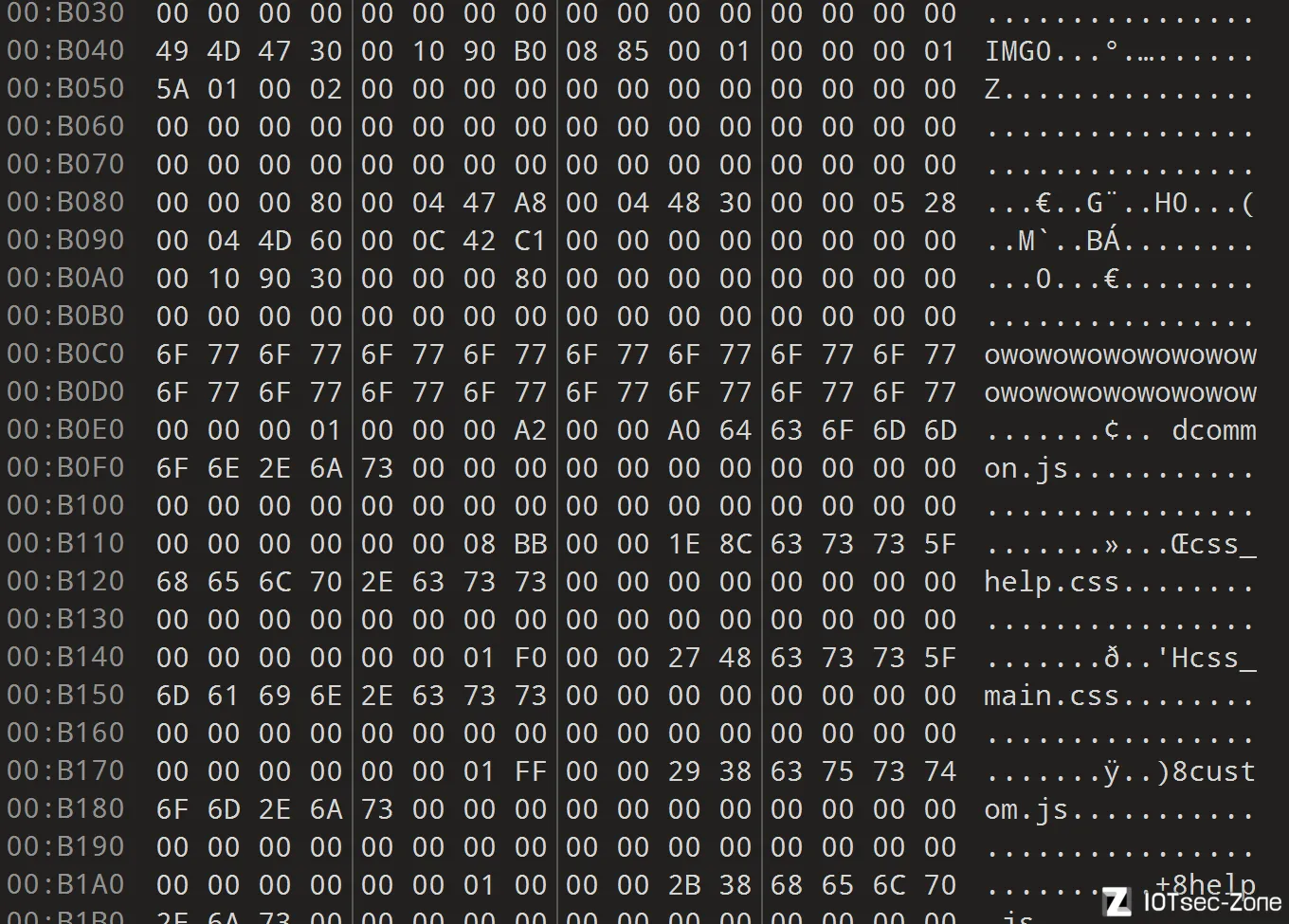
而万一有些文件里面如果有满足这种规则的坏字符串的话,还有最后两个办法:
长度限制(满足这些规则以外,文件名长度还必须>=5)
到最后的文件重命名环节,其需要确实对上了某个文件偏移才会被引用,否则会被丢弃
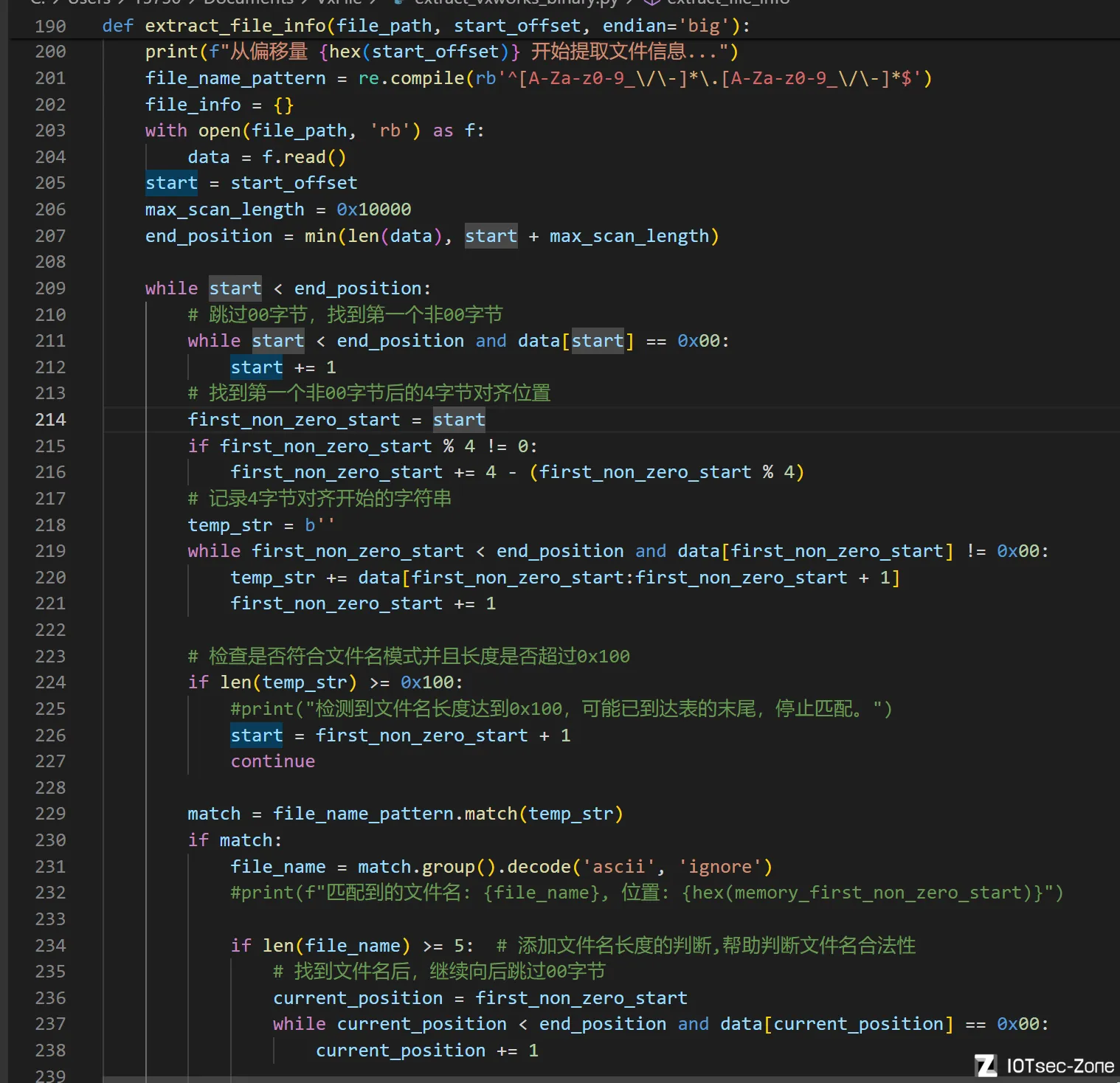
还有就是,怎么知道文件名提取到了末尾呢
其实就是,每次提取下一个文件名时,如果检测到连续0x100个非00字符,那就说明提取已经到尽头了,因为接下来就是下一个程序片段部分
正确恢复文件名
正确恢复文件名实际上还需要考虑到一件事:
一部分固件的文件名如下,是没有带路径的
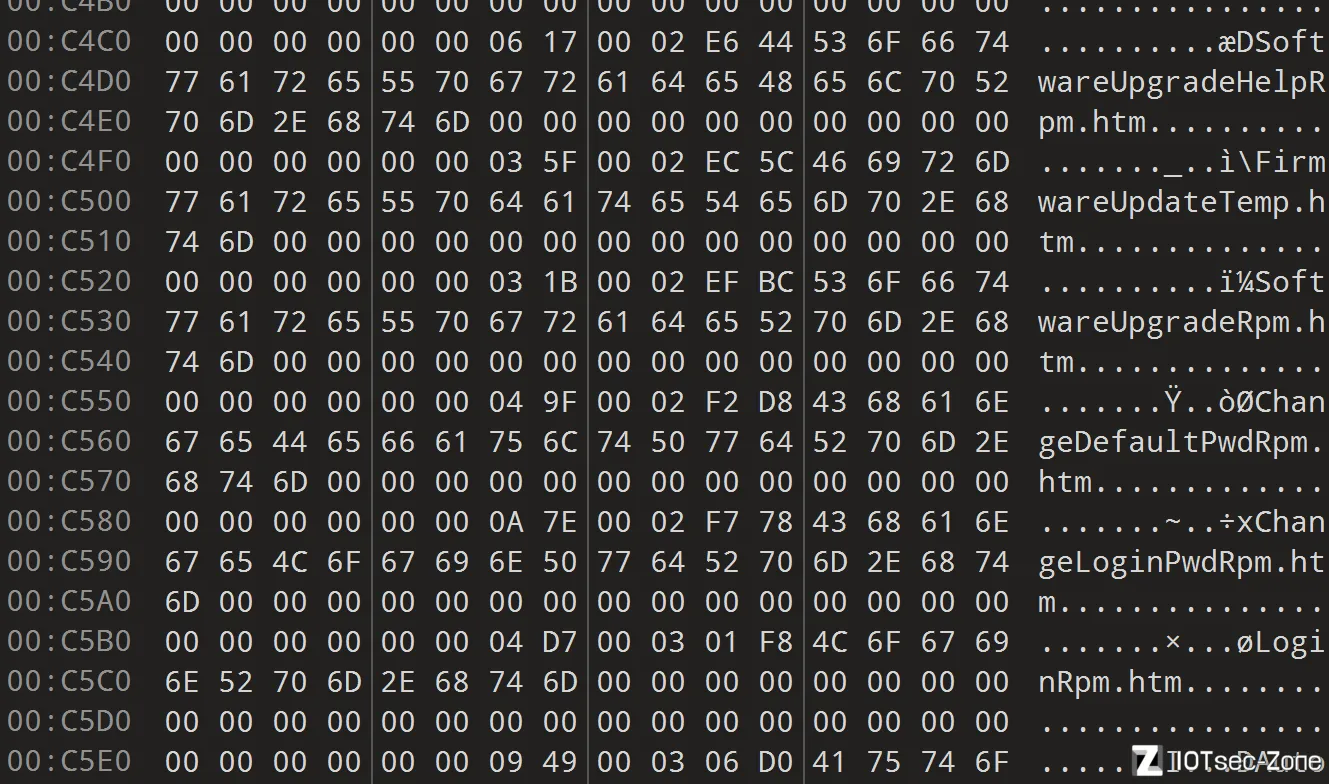
而另一些还是有的
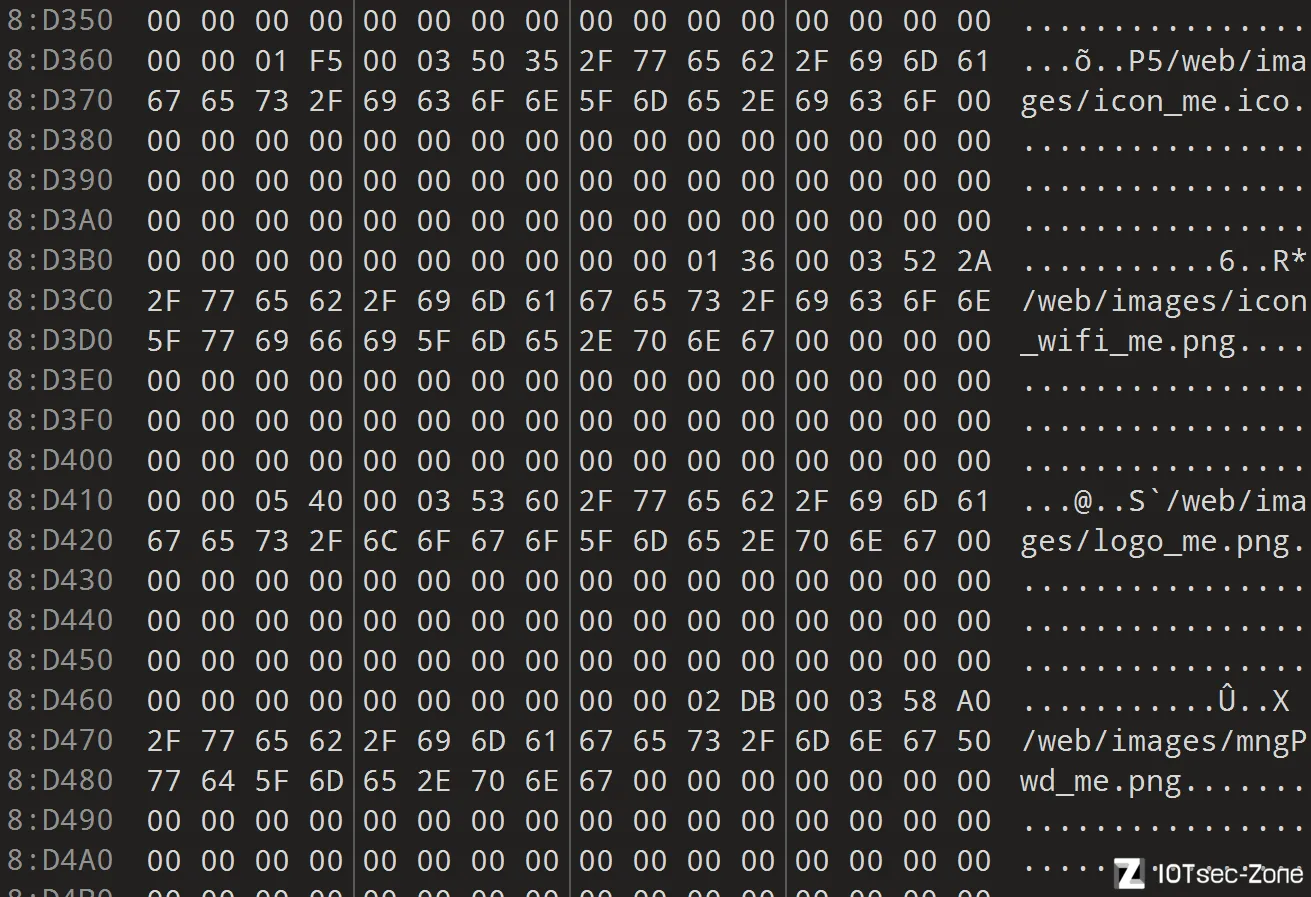
所以需要分情况处理
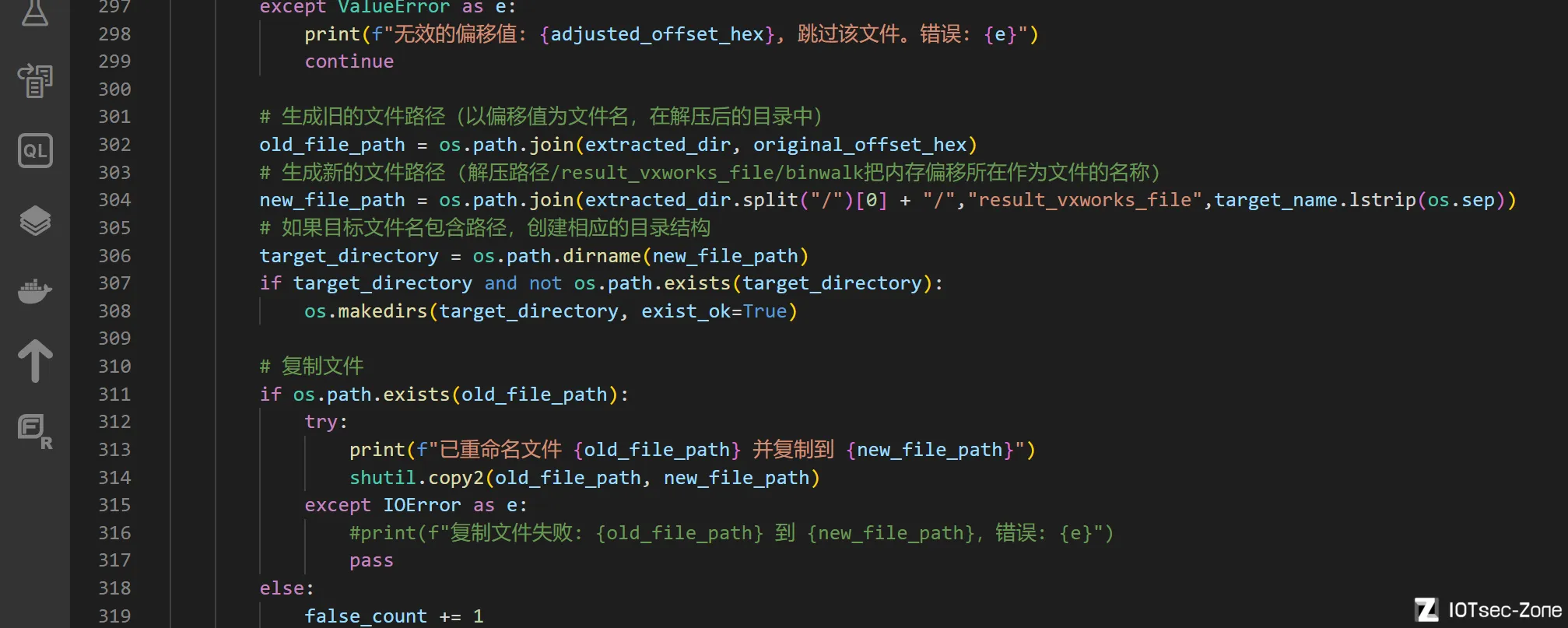
一键自动化vxworks文件提取和文件名恢复代码实现
最后,附上开源代码
https://github.com/0xba1100n/vxfile_extractor
效果图