
4. Fuzzing101 - 4 libtiff
1. 目标环境配置
cd $HOME/Desktop/Fuzz/training/
mkdir fuzzing_libtiff && cd fuzzing_libtiff/
# download and uncompress the target
wget https://download.osgeo.org/libtiff/tiff-4.0.4.tar.gz
tar -xzvf tiff-4.0.4.tar.gz
# make and install libtiff
cd tiff-4.0.4/
./configure --prefix="$HOME/Desktop/Fuzz/training/fuzzing_libtiff/install/" --disable-shared
make -j$(nproc)
make install
# test the target program
v4ler1an bin ➜ ./tiffinfo -D -j -c -r -s -w ../../tiff-4.0.4/test/images/palette-1c-1b.tiff
TIFF Directory at offset 0xbd4 (3028)
Image Width: 157 Image Length: 151
Bits/Sample: 1
Sample Format: unsigned integer
Compression Scheme: None
Photometric Interpretation: palette color (RGB from colormap)
Samples/Pixel: 1
Rows/Strip: 409
Planar Configuration: single image plane
Page Number: 0-1
Color Map:
0: 0 0 0
1: 65535 65535 65535
DocumentName: palette-1c-1b.tiff
Software: GraphicsMagick 1.2 unreleased Q16 http://www.GraphicsMagick.org/
1 Strips:
0: [ 8, 3020]
2. AFL++ 编译 target
2.1 常规编译
在不加代码覆盖率统计的情况下的编译:
rm -r $HOME/Desktop/Fuzz/training/fuzzing_tiff/install
cd $HOME/Desktop/Fuzz/training/fuzzing_tiff/tiff-4.0.4/
make clean
export LLVM_CONFIG="llvm-config-12"
CC=afl-clang-lto ./configure --prefix="$HOME/Desktop/Fuzz/training/fuzzing_tiff/install/" --disable-shared
# 开启AFL_USE_ASAN
AFL_USE_ASAN=1 make -j$(nproc)
AFL_USE_ASAN=1 make install
2.2 代码覆盖率
代码覆盖率是一种软件指标,表达了每行代码被触发的次数。在进行模糊测试的过程中,我们需要知道我们的 fuzzer 执行的效果怎么样,这个时候就可以使用上代码覆盖率。通过使用代码覆盖率,我们可以了解 fuzzer 已经到达了代码的哪些部分,并可视化 fuzzing 过程。
在这里我们使用 lcov 来展示代码覆盖率工具的使用。
lcov 是 gcc 测试覆盖率的前端图形展示工具。它通过收集多个源文件的 行、函数和分支的代码覆盖信息(程序执行之后生成gcda、gcno文件,上面的链接有讲) 并且将收集后的信息生成HTML页面。生成HTML需要使用genhtml命令。
# install
sudo apt instrall lcov
# usage info
v4ler1an bin ➜ lcov --help
Usage: lcov [OPTIONS]
Use lcov to collect coverage data from either the currently running Linux
kernel or from a user space application. Specify the --directory option to
get coverage data for a user space program.
Misc:
-h, --help Print this help, then exit
-v, --version Print version number, then exit
-q, --quiet Do not print progress messages
Operation:
-z, --zerocounters Reset all execution counts to zero
-c, --capture Capture coverage data
-a, --add-tracefile FILE Add contents of tracefiles
-e, --extract FILE PATTERN Extract files matching PATTERN from FILE
-r, --remove FILE PATTERN Remove files matching PATTERN from FILE
-l, --list FILE List contents of tracefile FILE
--diff FILE DIFF Transform tracefile FILE according to DIFF
--summary FILE Show summary coverage data for tracefiles
Options:
-i, --initial Capture initial zero coverage data
-t, --test-name NAME Specify test name to be stored with data
-o, --output-file FILENAME Write data to FILENAME instead of stdout
-d, --directory DIR Use .da files in DIR instead of kernel
-f, --follow Follow links when searching .da files
-k, --kernel-directory KDIR Capture kernel coverage data only from KDIR
-b, --base-directory DIR Use DIR as base directory for relative paths
--convert-filenames Convert filenames when applying diff
--strip DEPTH Strip initial DEPTH directory levels in diff
--path PATH Strip PATH from tracefile when applying diff
--(no-)checksum Enable (disable) line checksumming
--(no-)compat-libtool Enable (disable) libtool compatibility mode
--gcov-tool TOOL Specify gcov tool location
--ignore-errors ERRORS Continue after ERRORS (gcov, source, graph)
--no-recursion Exclude subdirectories from processing
--to-package FILENAME Store unprocessed coverage data in FILENAME
--from-package FILENAME Capture from unprocessed data in FILENAME
--no-markers Ignore exclusion markers in source code
--derive-func-data Generate function data from line data
--list-full-path Print full path during a list operation
--(no-)external Include (ignore) data for external files
--config-file FILENAME Specify configuration file location
--rc SETTING=VALUE Override configuration file setting
--compat MODE=on|off|auto Set compat MODE (libtool, hammer, split_crc)
--include PATTERN Include files matching PATTERN
--exclude PATTERN Exclude files matching PATTERN
For more information see: http://ltp.sourceforge.net/coverage/lcov.php
附带代码覆盖率重新构建 libtiff 库:
# rebuild libtiff
rm -r $HOME/Desktop/Fuzz/training/fuzzing_libtiff/install
cd $HOME/Desktop/Fuzz/training/fuzzing_libtiff/tiff-4.0.4/
make clean
# 添加代码覆盖率编译选项
CFLAGS="--coverage" LDFLAGS="--coverage" ./configure --prefix="$HOME/Desktop/Fuzz/training/fuzzing_libtiff/install/" --disable-shared
make -j$(nproc)
make install
然后是收集覆盖率信息:
cd $HOME/Desktop/Fuzz/training/fuzzing_tiff/tiff-4.0.4/
lcov --zerocounters --directory ./ # 重置计数器
lcov --capture --initial --directory ./ --output-file app.info # 返回“基线”覆盖数据文件,其中包含每个检测行的零覆盖
$HOME/Desktop/Fuzz/training/fuzzing_tiff/install/bin/tiffinfo -D -j -c -r -s -w $HOME/Desktop/Fuzz/training/fuzzing_tiff/tiff-4.0.4/test/images/palette-1c-1b.tiff
lcov --no-checksum --directory ./ --capture --output-file app2.info #将当前覆盖状态保存到 app2.info 文件中
# 生成的代码覆盖率信息文件
v4ler1an tiff-4.0.4 ➜ file app.info
app.info: LCOV coverage tracefile
v4ler1an tiff-4.0.4 ➜ file app2.info
app2.info: LCOV coverage tracefile
v4ler1an tiff-4.0.4 ➜ head -n 20 app.info
TN:
SF:/home/v4ler1an/Desktop/Fuzz/training/fuzzing_libtiff/tiff-4.0.4/contrib/dbs/tiff-rgb.c
FN:43,main
FNDA:0,main
FN:190,Usage
FNDA:0,Usage
DA:43,0
DA:45,0
DA:46,0
DA:53,0
DA:55,0
DA:56,0
DA:57,0
DA:58,0
DA:59,0
DA:60,0
DA:61,0
DA:62,0
DA:63,0
为了方便查看覆盖率信息,我们可以生成 html 文件方便查看:
v4ler1an tiff-4.0.4 ➜ genhtml --highlight --legend -output-directory ./html-coverage/ ./app2.info
v4ler1an tiff-4.0.4 ➜ cd html-coverage
v4ler1an html-coverage ➜ ls
amber.png gcov.css index.html index-sort-l.html ruby.png tools
emerald.png glass.png index-sort-f.html libtiff snow.png updown.png
浏览器查看生成的 index.html 文件可以看到代码覆盖率信息:
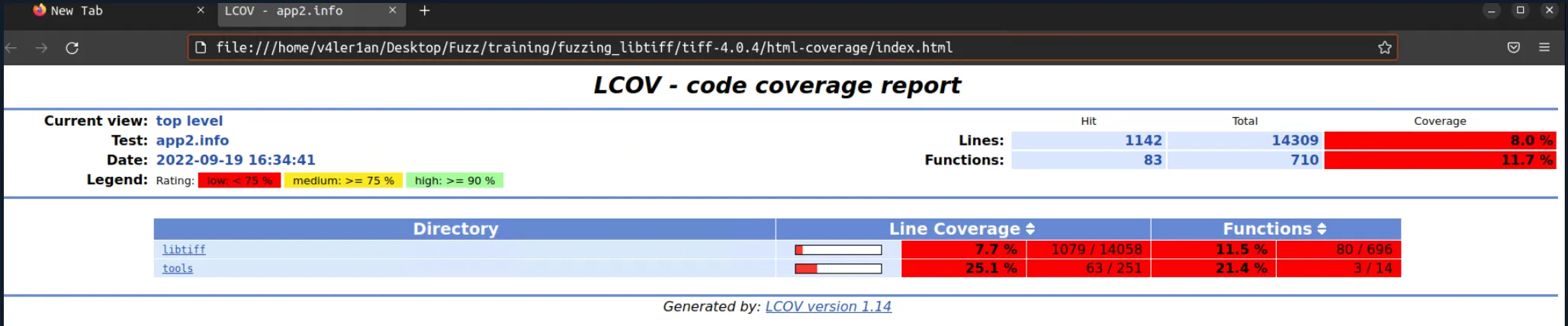
这里有 libtiff 和 tools 两个 directory,点开进去可以看到其中各个文件的统计结果:
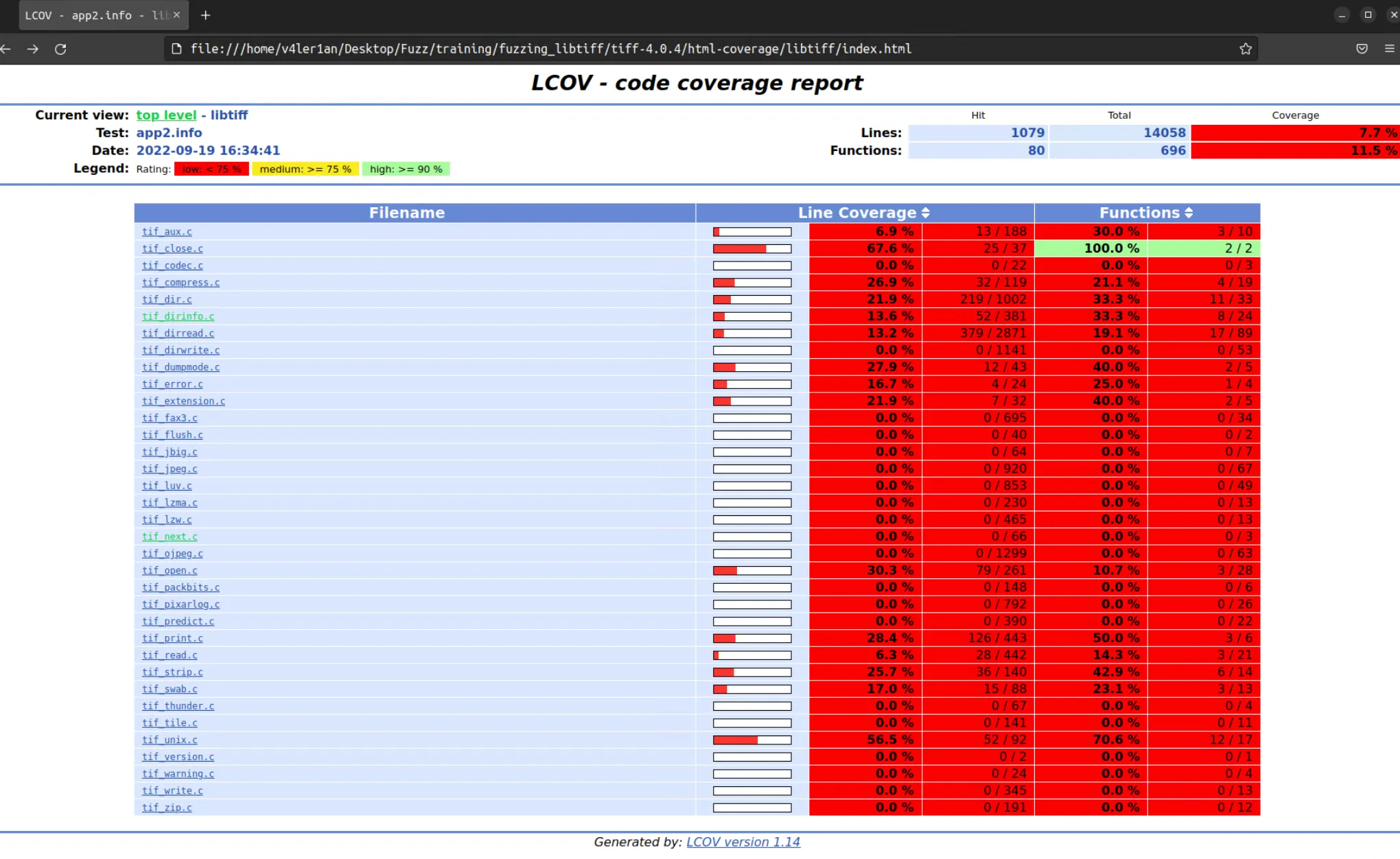
每个文件都是可以点开的,里面会记录哪些代码被执行了:
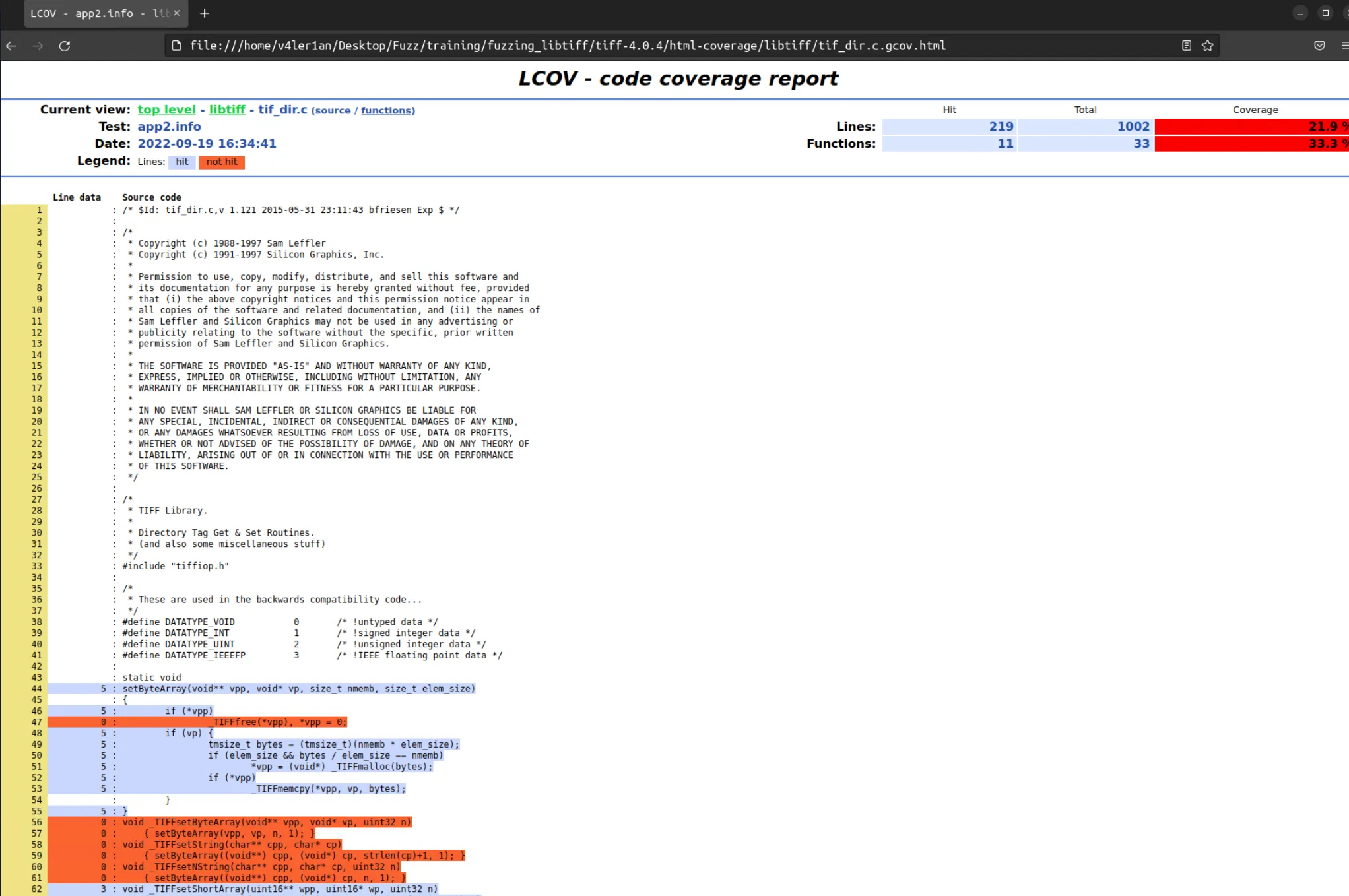
这些信息都是借助于 GCC 编译器的功能,十分方便我们去观察想要执行的代码是否有被执行到。
3. 执行 fuzz
首先我们来一个基础的 fuzz ,使用的编译为前面的常规的编译,测试用例直接使用 tiff 自带的 images 文件夹下的文件:
afl-fuzz -m none -i $HOME/Desktop/Fuzz/training/fuzzing_libtiff/tiff-4.0.4/test/images/ -o $HOME/Desktop/Fuzz/training/fuzzing_libtiff/out/ -s 123 -- $HOME/Desktop/Fuzz/training/fuzzing_libtiff/install/bin/tiffinfo -D -j -c -r -s -w @@
最终的执行结果如下:
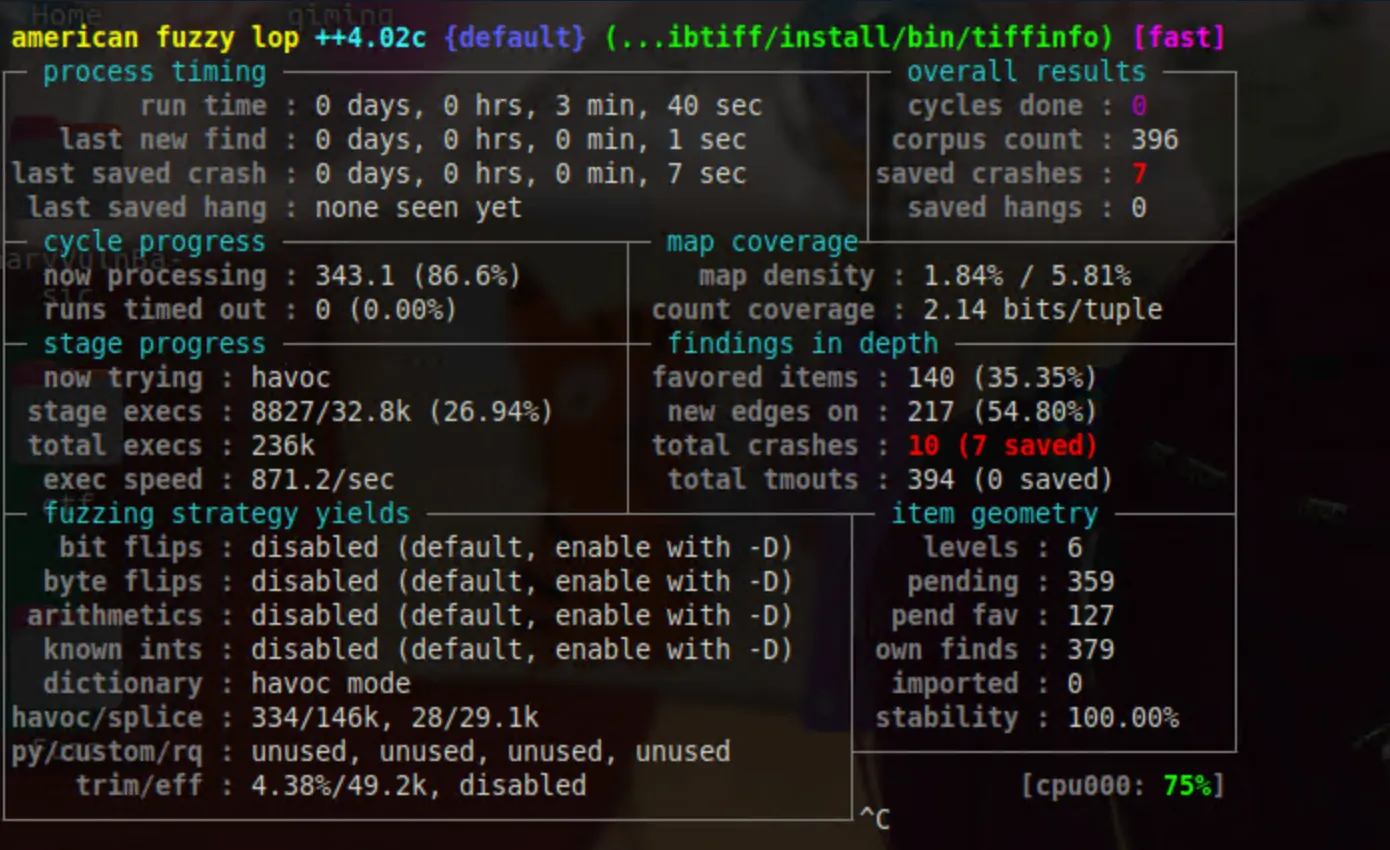
这里我们只是做说明,所以没有使用 Master-Slave 的模式。
然后我们再进行一个带覆盖率统计的 fuzz:
# AFL带覆盖率编译
rm -r $HOME/Desktop/Fuzz/training/fuzzing_tiff/install
cd $HOME/Desktop/Fuzz/training/fuzzing_tiff/tiff-4.0.4/
make clean
export LLVM_CONFIG="llvm-config-12"
CC=afl-gcc CFLAGS="--coverage" LDFLAGS="--coverage" ./configure --prefix="$HOME/Desktop/Fuzz/training/fuzzing_tiff/install/" --disable-shared
# 开启AFL_USE_ASAN
AFL_USE_ASAN=1 make -j$(nproc)
AFL_USE_ASAN=1 make install
lcov --zerocounters --directory ./ # 重置计数器
lcov --capture --initial --directory ./ --output-file app.info
afl-fuzz -m none -i $HOME/Desktop/Fuzz/training/fuzzing_libtiff/tiff-4.0.4/test/images/ -o $HOME/Desktop/Fuzz/training/fuzzing_libtiff/out/ -s 123 -- $HOME/Desktop/Fuzz/training/fuzzing_libtiff/install/bin/tiffinfo -D -j -c -r -s -w @@
lcov --no-checksum --directory ./ --capture --output-file app2.info
这里面的一个需要注意的点是,lcov是利用的 GCC 的一些功能,所以我们在指定 CC 的时候,需要使用 afl-gcc,而基于 llvm 的 afl-clang-fast/afl-clang-lto 都无法成功进行 lcov 的初始化,这也是 lcov 不方便的地方。
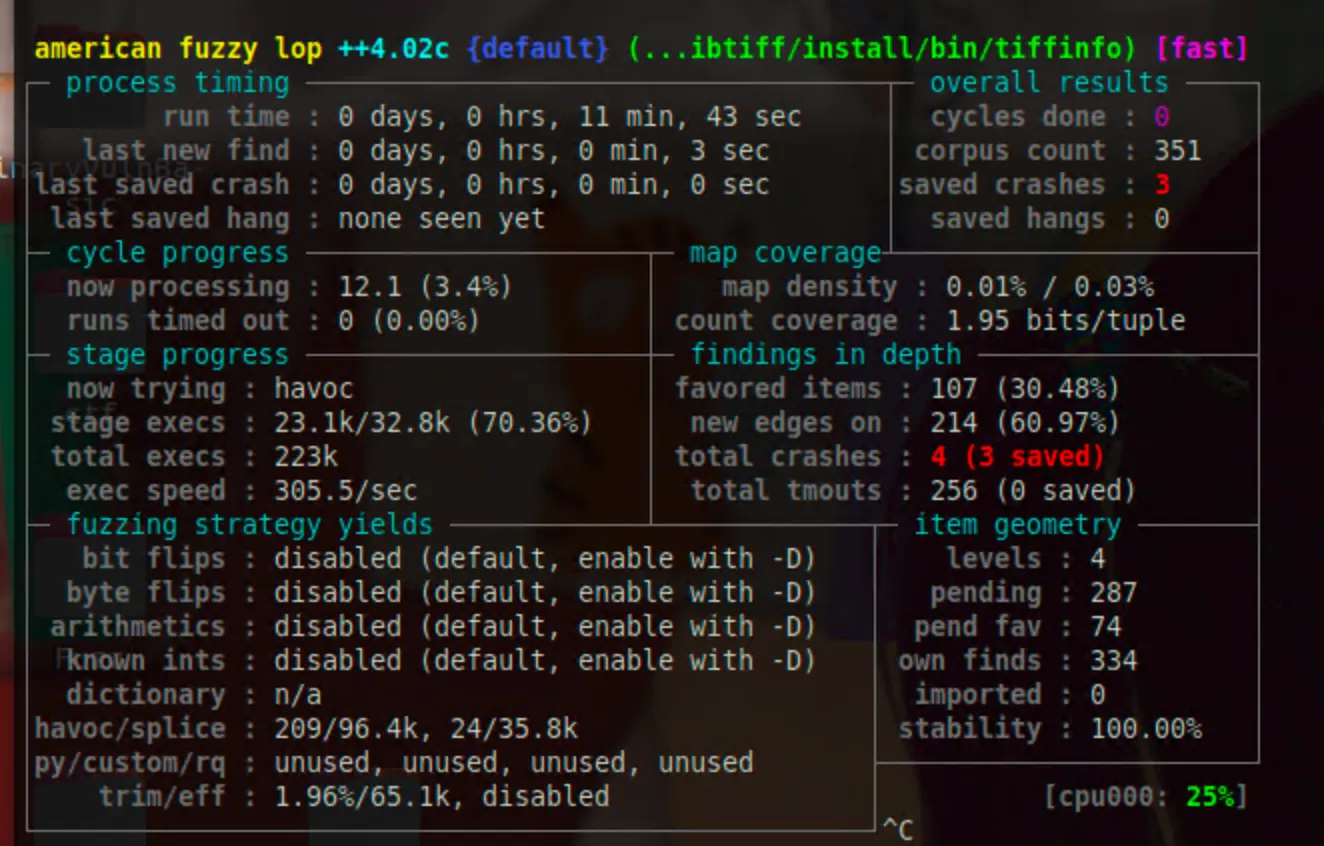
fuzz 的速度会变慢,所以这里可以使用 Master-Slave 模式来加快 fuzz 速度。
我们去看生成的 app2.info 覆盖率信息:
genhtml --highlight --legend -output-directory ./html-coverage/ ./app2.info
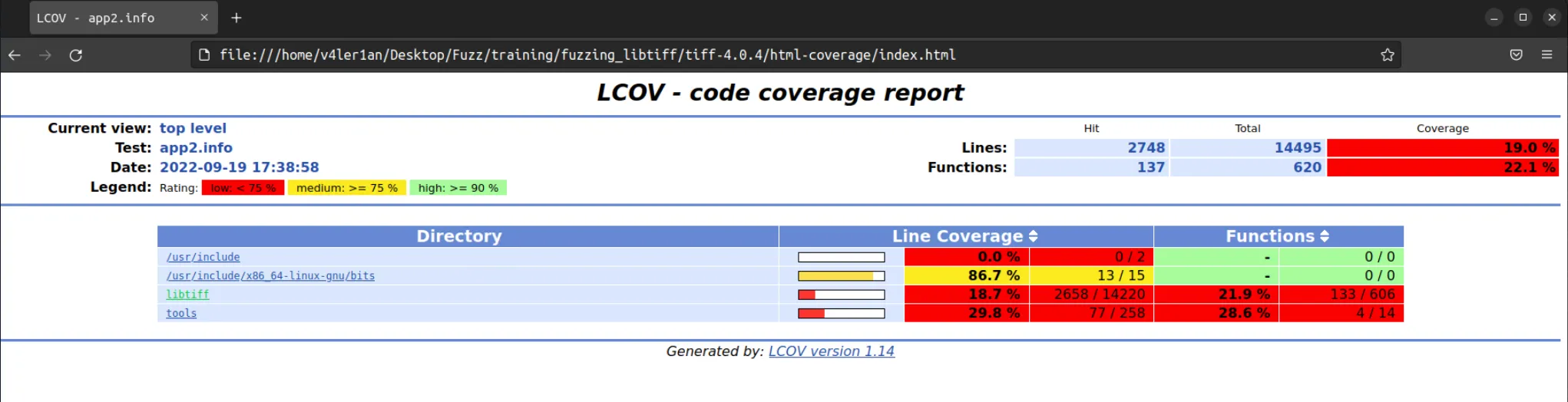
整体上看,这个覆盖率还是比较低的。
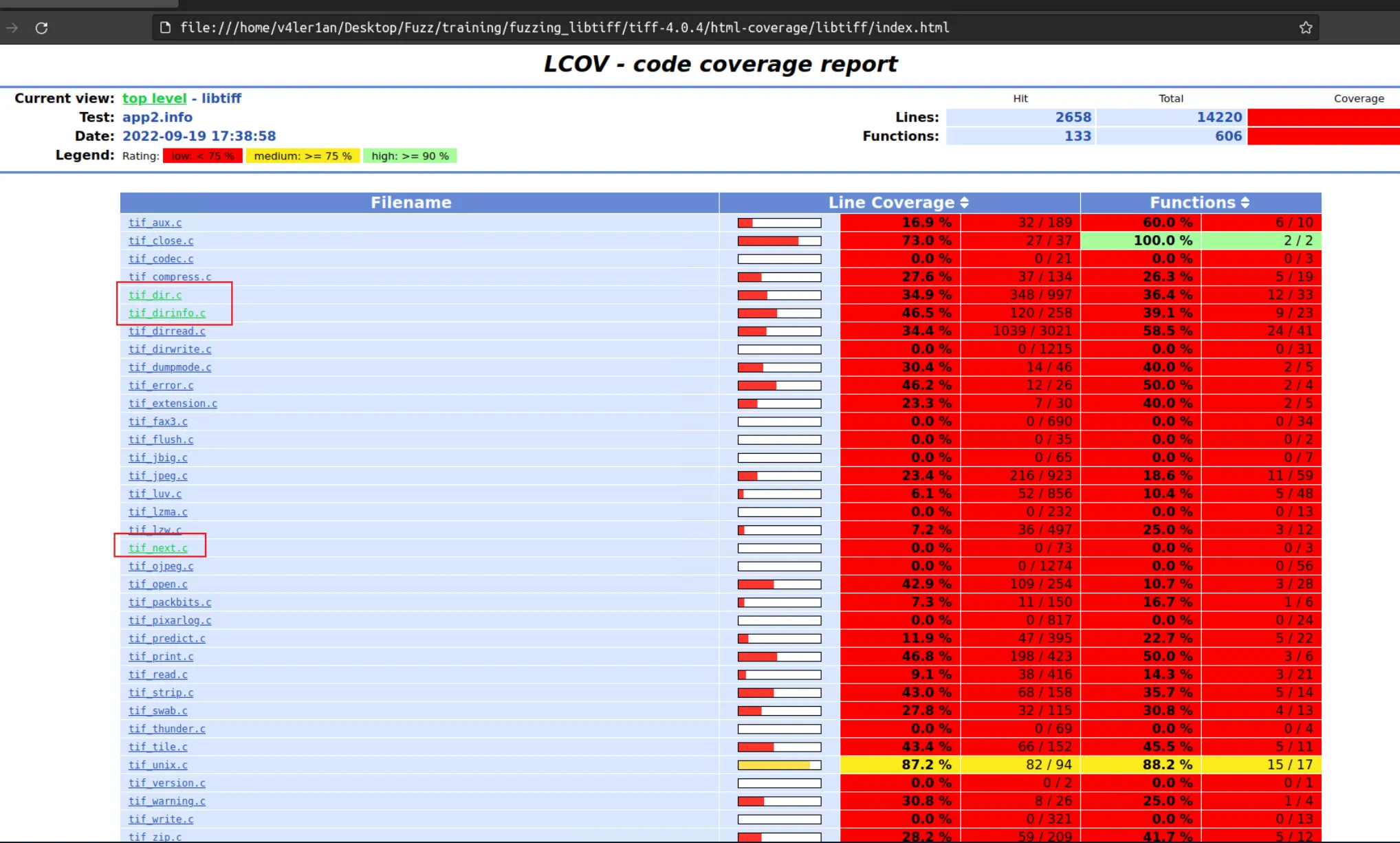
但是我们的主要目标 tif_dirinfo.c 文件的覆盖率效果还是可以接受的,都超过了1/3,而且我们的 fuzz 的时间并不是很长,如果继续下去,应该是可以覆盖到更多的代码的。对于文件执行到的具体代码,可以进入到文件里面再查看详细信息。
4. crash 分析
ASan 追踪结果如下:
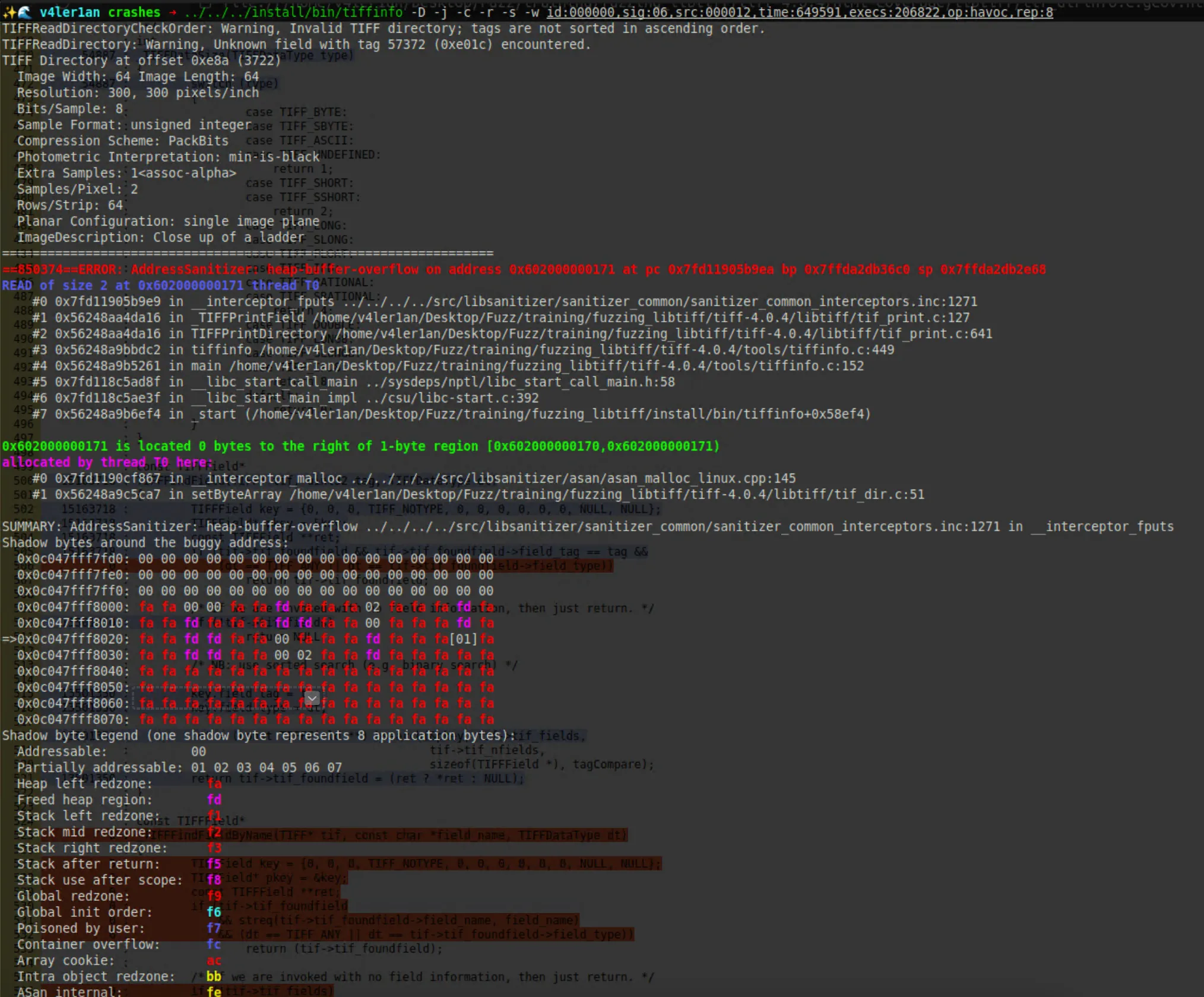
现在可以在重现 crash 的前提下,再加上 lcov 提供的代码覆盖率,就可以更轻松地去定位漏洞触发的原因了。
5. 总结
在这个练习中,引入了代码覆盖率的概念和工具。除了本例使用的 lcov 之外,还有一个常见的 GCC 的 gcov,但是其图形化信息不如 lcov 丰富。代码覆盖率对于 AFL 这种基于覆盖引导的 fuzzer 来说,意义重大,判定 fuzzer 效果好坏的关键因素之一就是看其代码覆盖率的高低。在对 fuzzer 进行优化和改进时,往往也是朝着可以提升代码覆盖率的方向去更改,毕竟执行越多的代码,越有可能发现更多的问题。
但是根据我们前面的测试也可以发现,在使用编译器编译时,只能使用 gcc 系,这样会造成一定程度上的速度损耗,这其中的衡量就需要使用者根据实际情况来进行取舍了。
5. Fuzzing101 - 5 lixml2
1. 目标环境配置
cd $HOME
mkdir Fuzzing_libxml2 && cd Fuzzing_libxml2
# download and uncompress the target
wget http://xmlsoft.org/download/libxml2-2.9.4.tar.gz
tar xvf libxml2-2.9.4.tar.gz && cd libxml2-2.9.4/
# build and install libxml
sudo apt-get install python-dev
CC=afl-clang-lto CXX=afl-clang-lto++ CFLAGS="-fsanitize=address" CXXFLAGS="-fsanitize=address" LDFLAGS="-fsanitize=address" ./configure --prefix="$HOME/Fuzzing_libxml2/libxml2-2.9.4/install" --disable-shared --without-debug --without-ftp --without-http --without-legacy --without-python LIBS='-ldl'
make -j$(nproc)
make install
# test the target program
./xmllint --memory ./test/wml.xml
(编译的时候可能会有点慢,这个库还是挺大的。当然,如果你有个性能卓越的machine就是另外一回事了。)
2. AFL++编译target
在上面的编译中已经使用 afl-clang-lto 进行了编译,所以无需再次编译。这里我们要介绍一下 afl 的另外一个功能 —— dictionary(字典)。
当我们想要 fuzz 复杂的基于文本的文件格式(例如 xml)时,我们可以为 fuzzer 提供一个包含基本语法标记列表的 dictionary。对于 AFL/AFL++ 来说,dictionary是一组单词或者其他的值,这些会指导 AFL/AFL++ 将变异应用到内存文件中。
- Override:用 n 个字节替换特定位置,其中 n 是字典条目的长度
- Insert:在当前文件位置插入字典条目,强制所有字符向下移动 n 个位置并增加文件大小
白话讲就是告诉 AFL 应该基于什么模版去进行变异,变异后的数据要符合模版的相关结构。
我们在本例中使用的是 AFLplusplus 中自带的一个 xml.dict 来作为 dictionary。
3. 执行fuzz
因为 libxml2 库较大,所以这里使用 Master-Slave 模式进行 fuzz:
afl-fuzz -m none -i /home/v4ler1an/Desktop/Fuzz/training/fuzzing_libxml2/libxml2_in -o out -s 123 -x /home/v4ler1an/Desktop/Fuzz/AFLplusplus/dictionaries/xml.dict -M master -- ./xmllint --memory --noenc --nocdata --dtdattr --loaddtd --valid --xinclude @@
afl-fuzz -m none -i /home/v4ler1an/Desktop/Fuzz/training/fuzzing_libxml2/libxml2_in -o out -s 123 -x /home/v4ler1an/Desktop/Fuzz/AFLplusplus/dictionaries/xml.dict -S slave1 -- ./xmllint --memory --noenc --nocdata --dtdattr --loaddtd --valid --xinclude @@
afl-fuzz -m none -i /home/v4ler1an/Desktop/Fuzz/training/fuzzing_libxml2/libxml2_in -o out -s 123 -x /home/v4ler1an/Desktop/Fuzz/AFLplusplus/dictionaries/xml.dict -S slave2 -- ./xmllint --memory --noenc --nocdata --dtdattr --loaddtd --valid --xinclude @@
afl-fuzz -m none -i /home/v4ler1an/Desktop/Fuzz/training/fuzzing_libxml2/libxml2_in -o out -s 123 -x /home/v4ler1an/Desktop/Fuzz/AFLplusplus/dictionaries/xml.dict -S slave3 -- ./xmllint --memory --noenc --nocdata --dtdattr --loaddtd --valid --xinclude @@
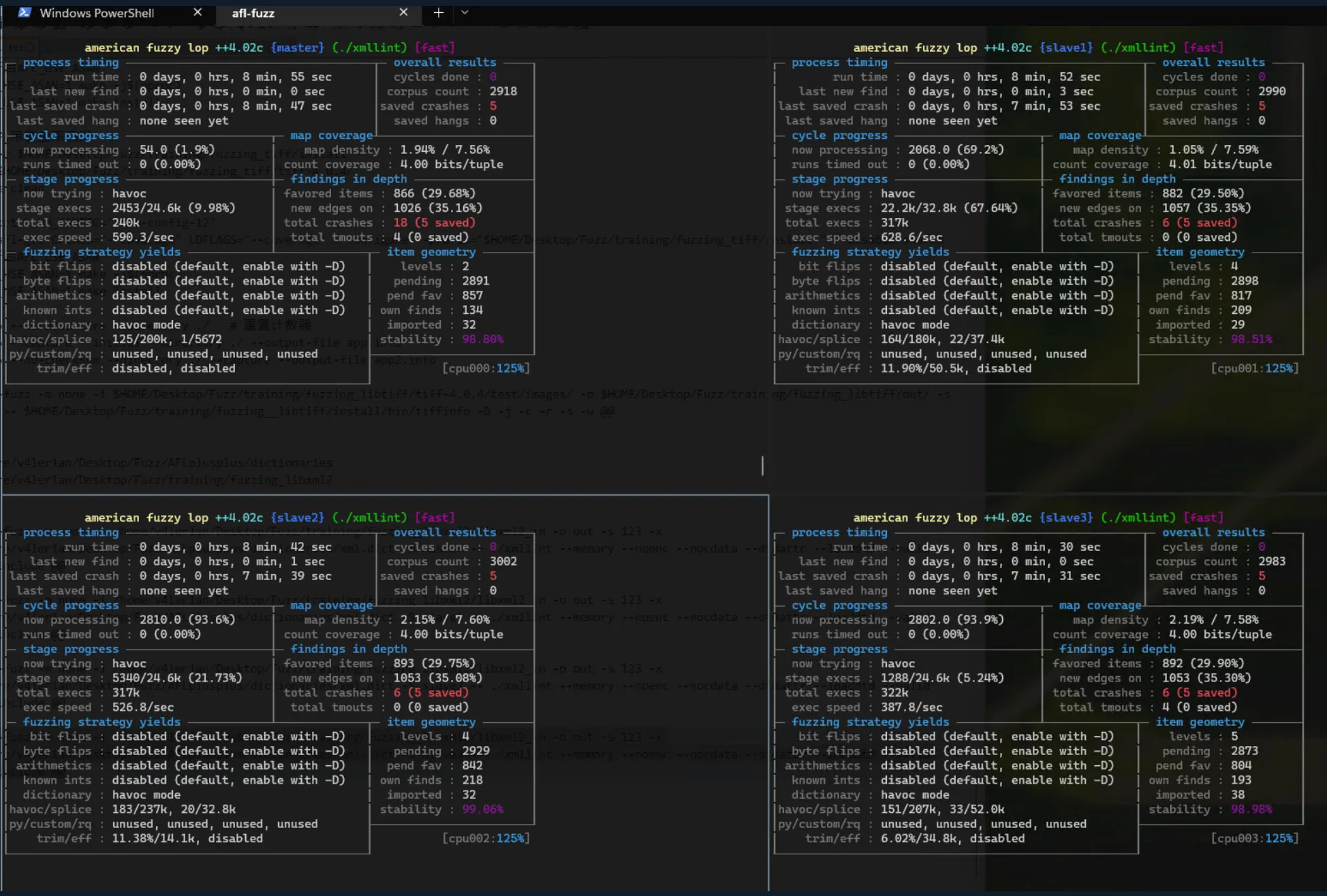
4. 总结
在这个例子里我们主要关注的是 AFL 中的 dictionary 的概念,在面对格式复杂、体量较大的基于文本的文件的 fuzz 时,如果只是单纯使用 AFL 内置的各种变异策略进行种子变异,无疑会浪费很多资源,因为会产生大量的无效输入,比如根本不符合目标程序输入要求的文件内容。所以在这种情况下,最好能够有一个模版性质的东西先将输入进行一次过滤或者限制变异的方向和内容,这就是 dictionary的作用。其实到这里为止,有一点结构化 fuzz 的含义在里面,不再是单纯的无意义的变异。可能功能本身现在看起来没有什么特殊之处,但是这里面蕴含的哲学思想还是值得我们去思考学习的:化繁为简,结构拼合。



